

Volcano概览
今天要开始做LFX mentorship了,需要先学习一下Volcano调度器的具体细节。通过写这篇文档记录一下。
整个调度器的总体架构:
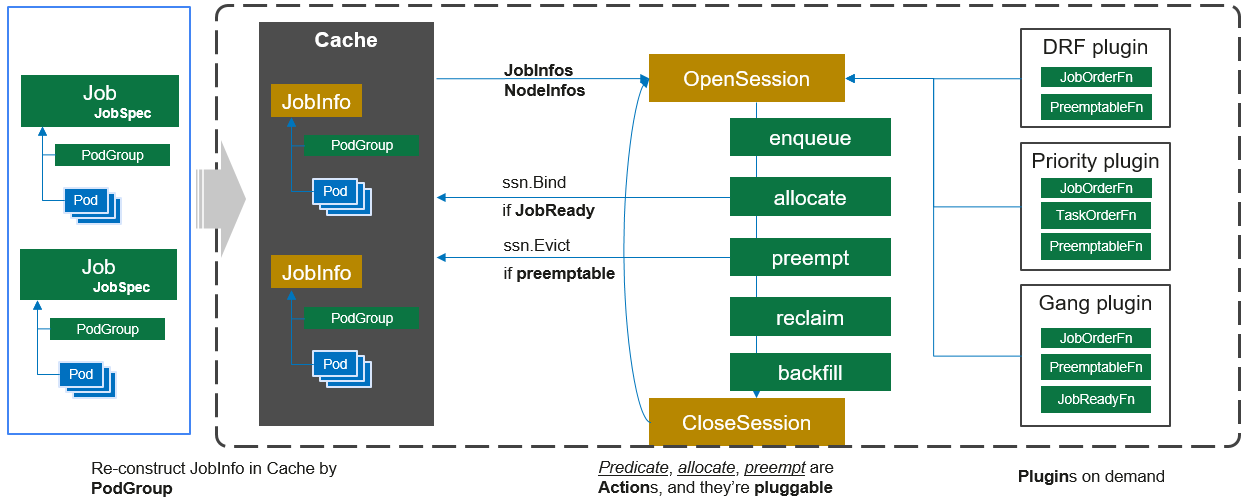
1、OpenSession
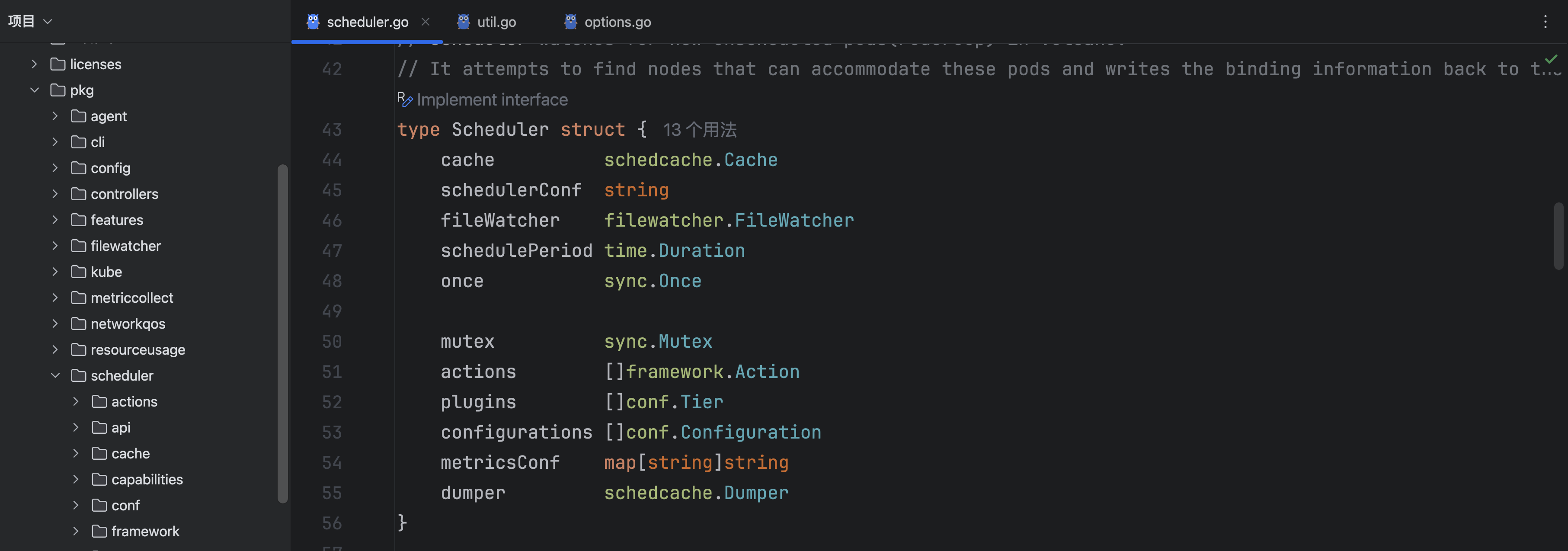
首先看一下scheduler的结构:
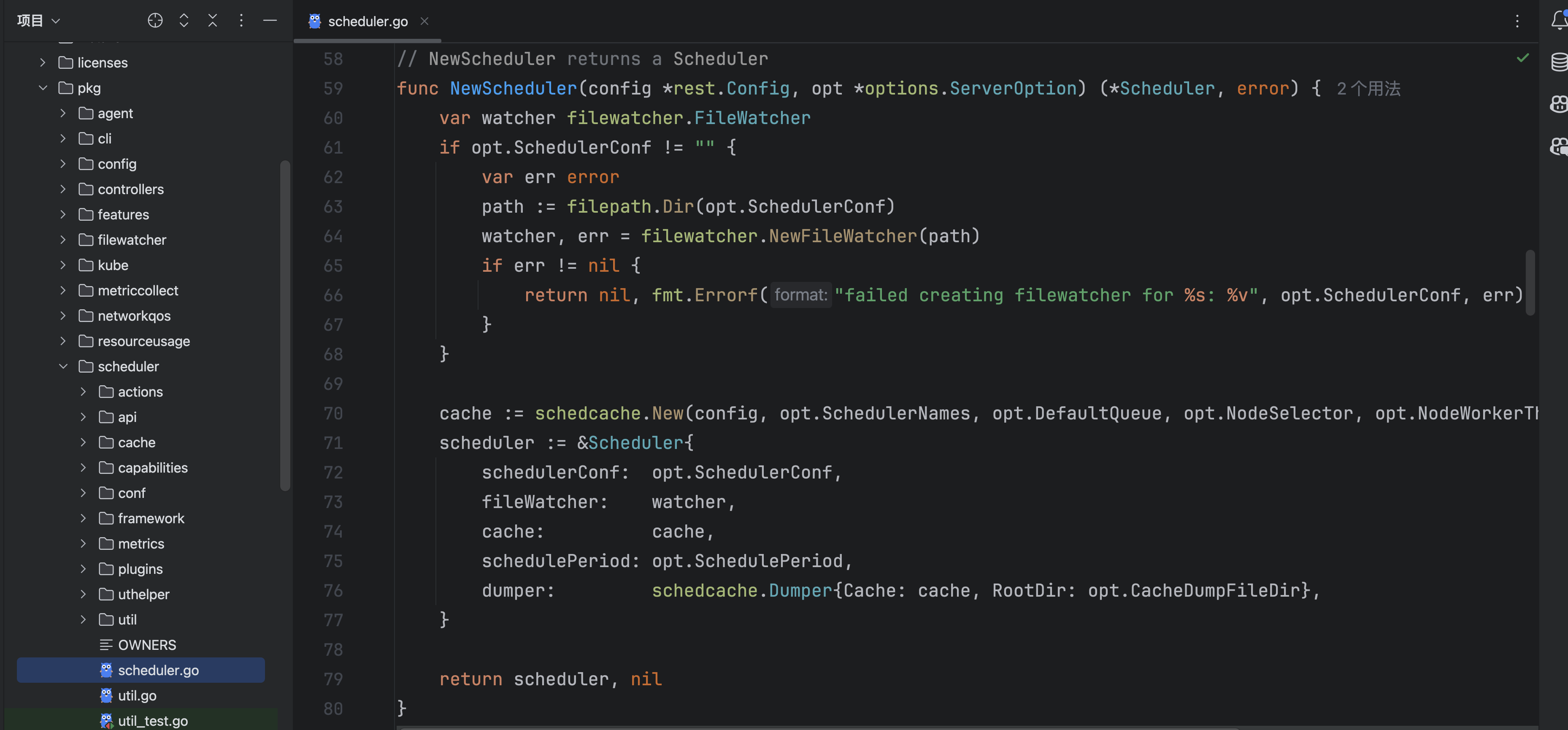
然后是New函数:
接着scheduler开始运行:
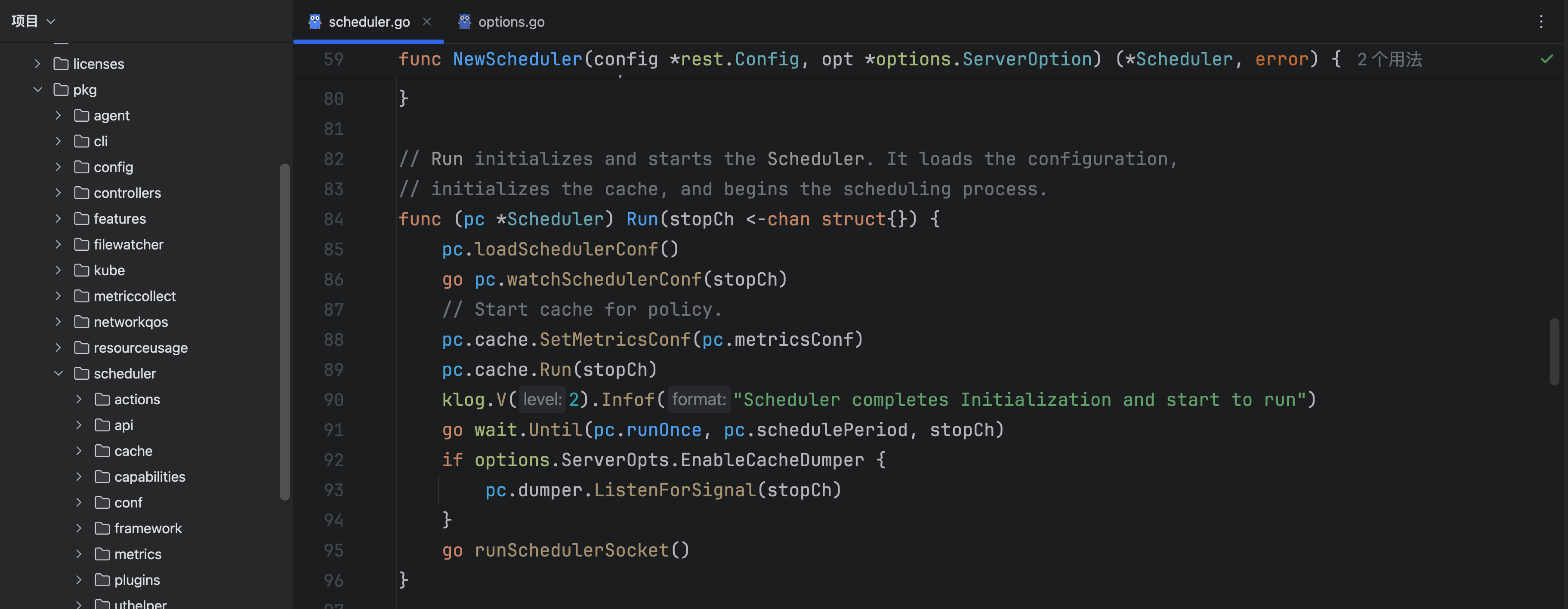
在运行的时候,首先要读取schedulerconf文件,这是一个configmap的配置文件,用来配置调度器采用的action和plugin:
func (pc *Scheduler) loadSchedulerConf() {
klog.V(4).Infof("Start loadSchedulerConf ...")
defer func() {
actions, plugins := pc.getSchedulerConf()
klog.V(2).Infof("Successfully loaded Scheduler conf, actions: %v, plugins: %v", actions, plugins)
}()
var err error
pc.once.Do(func() {
pc.actions, pc.plugins, pc.configurations, pc.metricsConf, err = UnmarshalSchedulerConf(DefaultSchedulerConf)
if err != nil {
klog.Errorf("unmarshal Scheduler config %s failed: %v", DefaultSchedulerConf, err)
panic("invalid default configuration")
}
})
var config string
if len(pc.schedulerConf) != 0 {
confData, err := os.ReadFile(pc.schedulerConf)
if err != nil {
klog.Errorf("Failed to read the Scheduler config in '%s', using previous configuration: %v",
pc.schedulerConf, err)
return
}
config = strings.TrimSpace(string(confData))
}
actions, plugins, configurations, metricsConf, err := UnmarshalSchedulerConf(config)
if err != nil {
klog.Errorf("Scheduler config %s is invalid: %v", config, err)
return
}
pc.mutex.Lock()
pc.actions = actions
pc.plugins = plugins
pc.configurations = configurations
pc.metricsConf = metricsConf
pc.mutex.Unlock()
}可以发现,如果没有自己指定的conf,就会采用defaultschedulerconf:
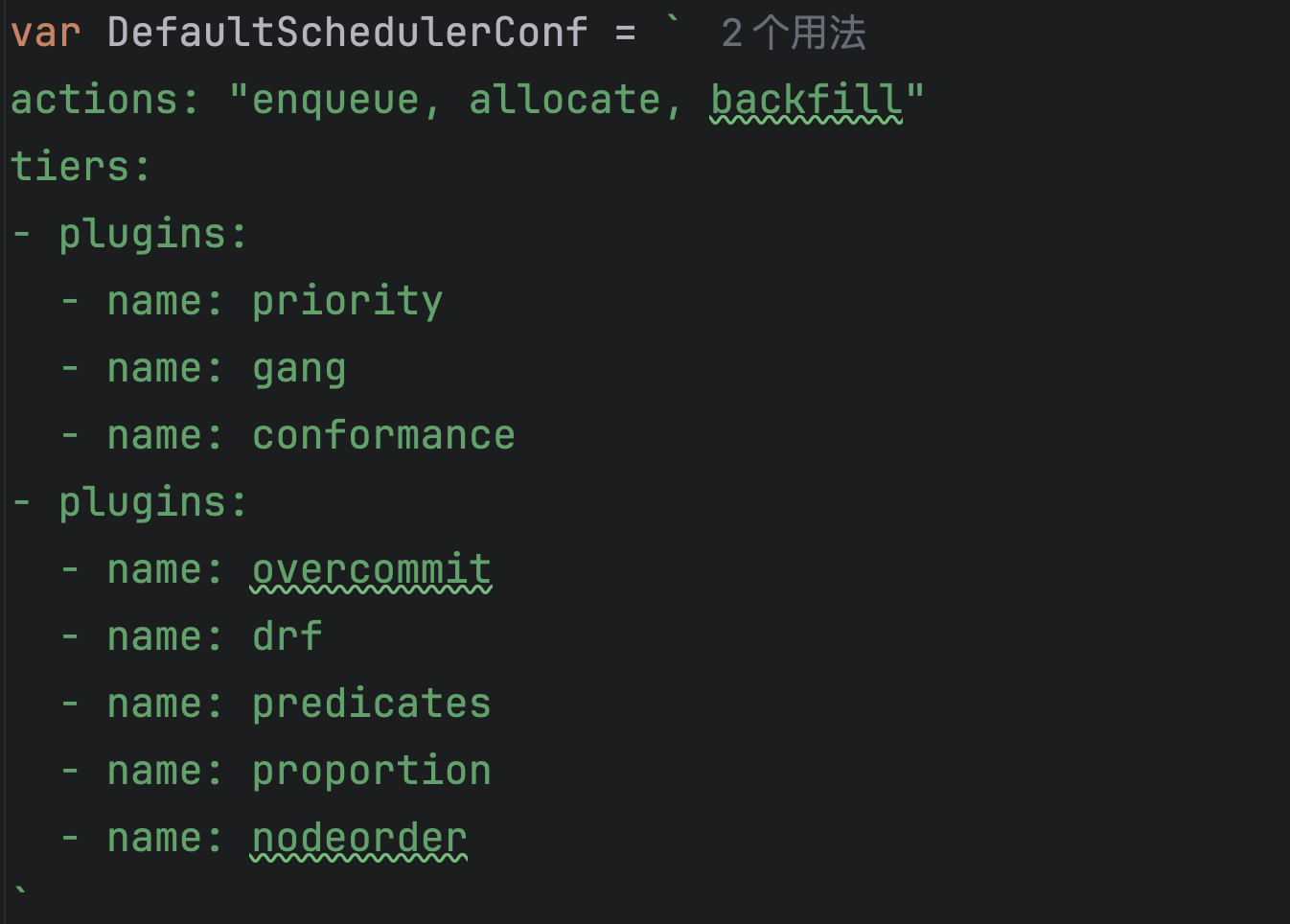
这个默认的schedulerconf就是采用enqueue、allocate、backfill这三个action。
通过读取这个全局的调度器配置文件,action和plugin就存到scheduler里面了。
接下来继续进行Run函数:
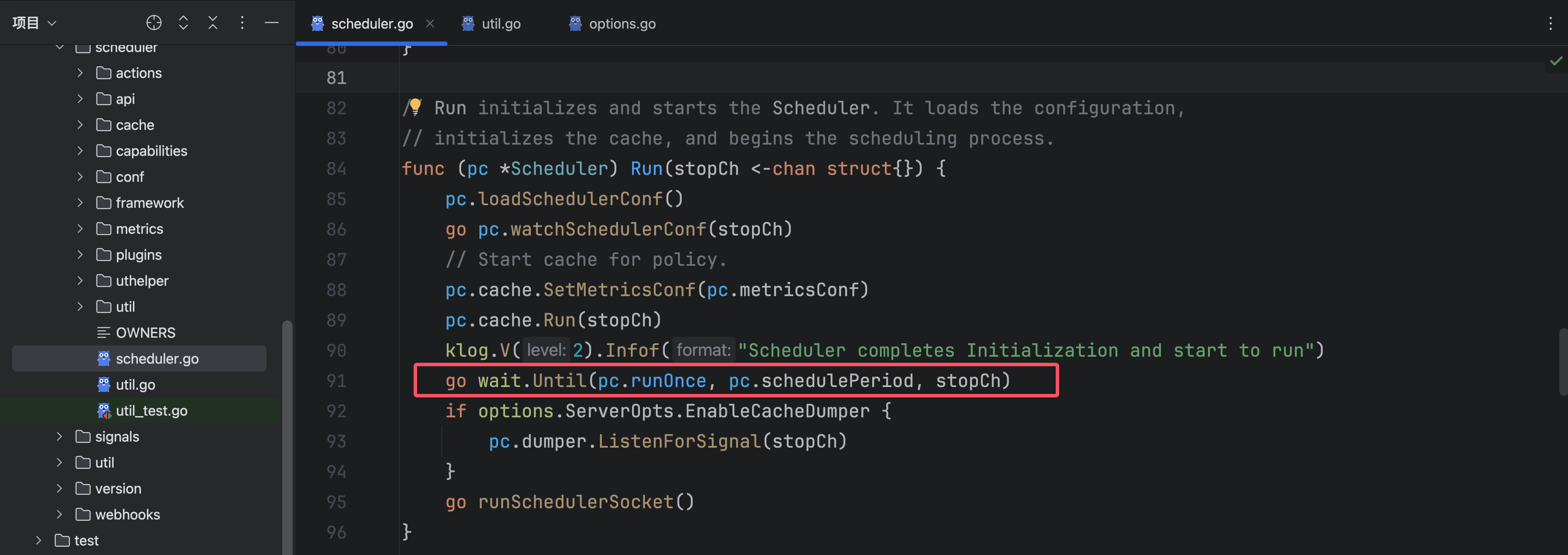
这个goroutine会间隔schedulePeriod执行一次runOnce函数,可以发现默认的schedulePeriod是一秒,也就是一秒进行一次调度:
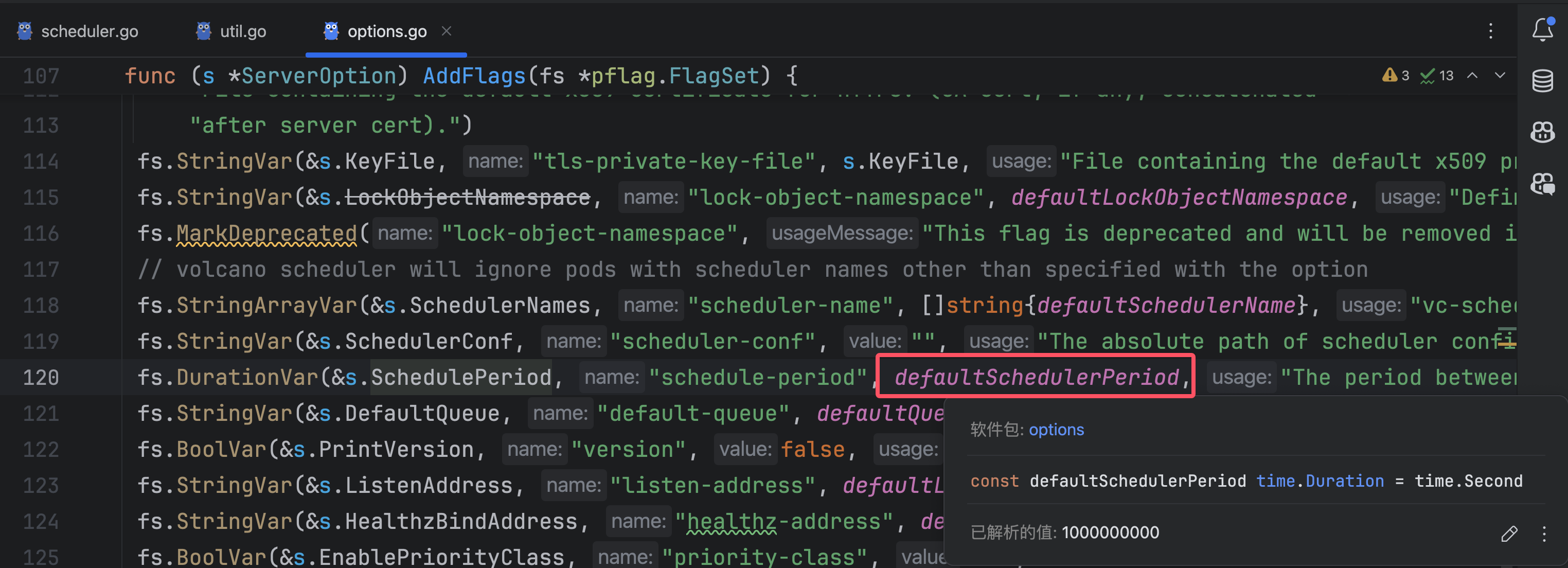
一次调度函数:
// runOnce executes a single scheduling cycle. This function is called periodically
// as defined by the Scheduler's schedule period.
func (pc *Scheduler) runOnce() {
klog.V(4).Infof("Start scheduling ...")
scheduleStartTime := time.Now()
defer klog.V(4).Infof("End scheduling ...")
pc.mutex.Lock()
actions := pc.actions
plugins := pc.plugins
configurations := pc.configurations
pc.mutex.Unlock()
// Load ConfigMap to check which action is enabled.
conf.EnabledActionMap = make(map[string]bool)
for _, action := range actions {
conf.EnabledActionMap[action.Name()] = true
}
ssn := framework.OpenSession(pc.cache, plugins, configurations)
defer func() {
framework.CloseSession(ssn)
metrics.UpdateE2eDuration(metrics.Duration(scheduleStartTime))
}()
for _, action := range actions {
actionStartTime := time.Now()
action.Execute(ssn)
metrics.UpdateActionDuration(action.Name(), metrics.Duration(actionStartTime))
}
}发现了一个函数OpenSession:
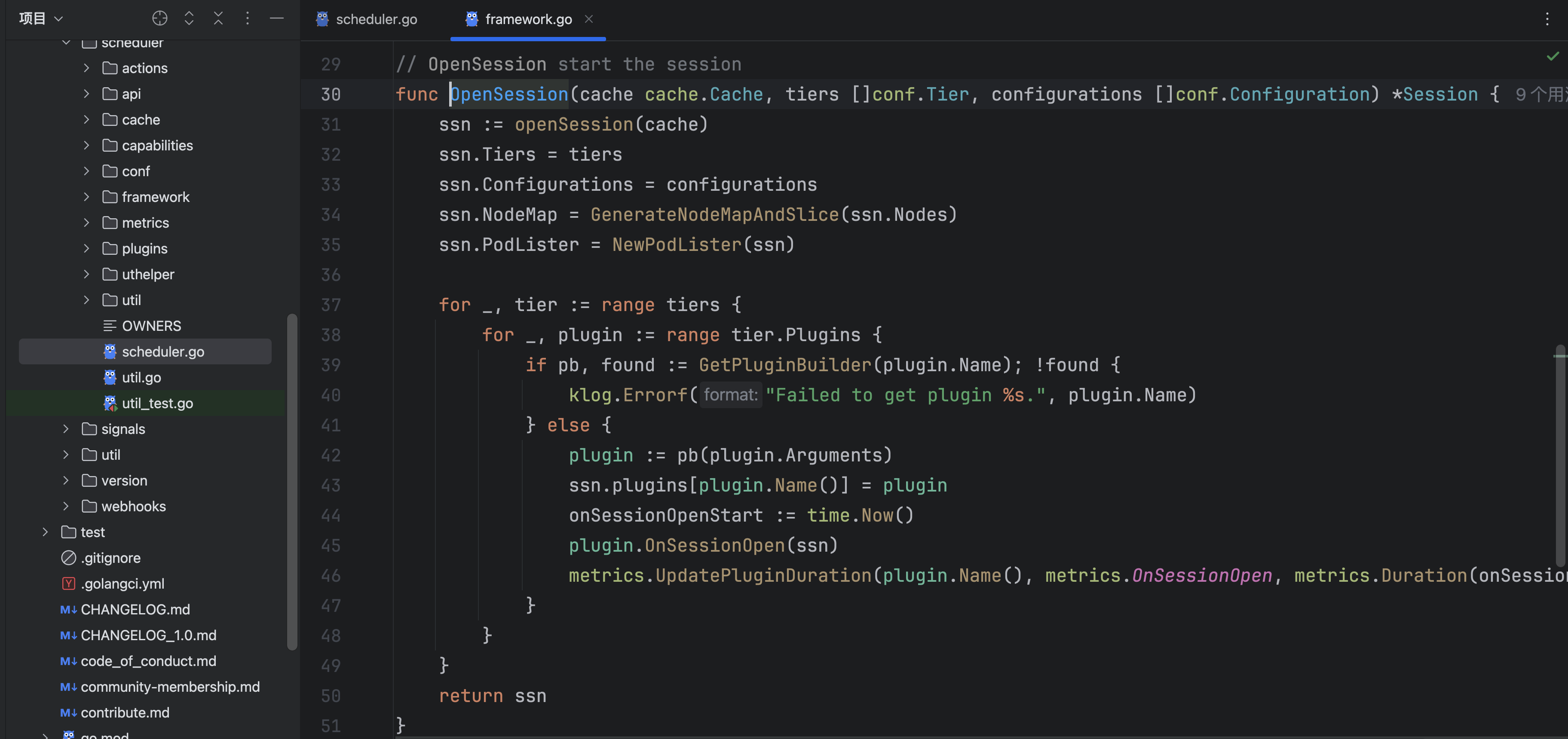
根据Volcano的调度架构图,OpenSession是调度的开始,第一步就是根据cache去获得了一个session:
session这个结构体就代表了一次调度(一秒一次的),也就是一次会话:
// Session information for the current session
type Session struct {
UID types.UID
kubeClient kubernetes.Interface
vcClient vcclient.Interface
recorder record.EventRecorder
cache cache.Cache
restConfig *rest.Config
informerFactory informers.SharedInformerFactory
TotalResource *api.Resource
TotalGuarantee *api.Resource
// podGroupStatus cache podgroup status during schedule
// This should not be mutated after initiated
podGroupStatus map[api.JobID]scheduling.PodGroupStatus
Jobs map[api.JobID]*api.JobInfo
Nodes map[string]*api.NodeInfo
CSINodesStatus map[string]*api.CSINodeStatusInfo
RevocableNodes map[string]*api.NodeInfo
Queues map[api.QueueID]*api.QueueInfo
NamespaceInfo map[api.NamespaceName]*api.NamespaceInfo
// NodeMap is like Nodes except that it uses k8s NodeInfo api and should only
// be used in k8s compatible api scenarios such as in predicates and nodeorder plugins.
NodeMap map[string]*k8sframework.NodeInfo
PodLister *PodLister
Tiers []conf.Tier
Configurations []conf.Configuration
NodeList []*api.NodeInfo
plugins map[string]Plugin
eventHandlers []*EventHandler
jobOrderFns map[string]api.CompareFn
queueOrderFns map[string]api.CompareFn
victimQueueOrderFns map[string]api.VictimCompareFn
taskOrderFns map[string]api.CompareFn
clusterOrderFns map[string]api.CompareFn
predicateFns map[string]api.PredicateFn
prePredicateFns map[string]api.PrePredicateFn
bestNodeFns map[string]api.BestNodeFn
nodeOrderFns map[string]api.NodeOrderFn
batchNodeOrderFns map[string]api.BatchNodeOrderFn
nodeMapFns map[string]api.NodeMapFn
nodeReduceFns map[string]api.NodeReduceFn
preemptableFns map[string]api.EvictableFn
reclaimableFns map[string]api.EvictableFn
overusedFns map[string]api.ValidateFn
// preemptiveFns means whether current queue can reclaim from other queue,
// while reclaimableFns means whether current queue's resources can be reclaimed.
preemptiveFns map[string]api.ValidateWithCandidateFn
allocatableFns map[string]api.AllocatableFn
jobReadyFns map[string]api.ValidateFn
jobPipelinedFns map[string]api.VoteFn
jobValidFns map[string]api.ValidateExFn
jobEnqueueableFns map[string]api.VoteFn
jobEnqueuedFns map[string]api.JobEnqueuedFn
targetJobFns map[string]api.TargetJobFn
reservedNodesFns map[string]api.ReservedNodesFn
victimTasksFns map[string][]api.VictimTasksFn
jobStarvingFns map[string]api.ValidateFn
}openSession这个函数接收cache,返回一个session,是通过对cache做一次快照:
func openSession(cache cache.Cache) *Session {
ssn := &Session{
UID: uuid.NewUUID(),
kubeClient: cache.Client(),
vcClient: cache.VCClient(),
restConfig: cache.ClientConfig(),
recorder: cache.EventRecorder(),
cache: cache,
informerFactory: cache.SharedInformerFactory(),
TotalResource: api.EmptyResource(),
TotalGuarantee: api.EmptyResource(),
podGroupStatus: map[api.JobID]scheduling.PodGroupStatus{},
Jobs: map[api.JobID]*api.JobInfo{},
Nodes: map[string]*api.NodeInfo{},
CSINodesStatus: map[string]*api.CSINodeStatusInfo{},
RevocableNodes: map[string]*api.NodeInfo{},
Queues: map[api.QueueID]*api.QueueInfo{},
plugins: map[string]Plugin{},
jobOrderFns: map[string]api.CompareFn{},
queueOrderFns: map[string]api.CompareFn{},
victimQueueOrderFns: map[string]api.VictimCompareFn{},
taskOrderFns: map[string]api.CompareFn{},
clusterOrderFns: map[string]api.CompareFn{},
predicateFns: map[string]api.PredicateFn{},
prePredicateFns: map[string]api.PrePredicateFn{},
bestNodeFns: map[string]api.BestNodeFn{},
nodeOrderFns: map[string]api.NodeOrderFn{},
batchNodeOrderFns: map[string]api.BatchNodeOrderFn{},
nodeMapFns: map[string]api.NodeMapFn{},
nodeReduceFns: map[string]api.NodeReduceFn{},
preemptableFns: map[string]api.EvictableFn{},
reclaimableFns: map[string]api.EvictableFn{},
overusedFns: map[string]api.ValidateFn{},
preemptiveFns: map[string]api.ValidateWithCandidateFn{},
allocatableFns: map[string]api.AllocatableFn{},
jobReadyFns: map[string]api.ValidateFn{},
jobPipelinedFns: map[string]api.VoteFn{},
jobValidFns: map[string]api.ValidateExFn{},
jobEnqueueableFns: map[string]api.VoteFn{},
jobEnqueuedFns: map[string]api.JobEnqueuedFn{},
targetJobFns: map[string]api.TargetJobFn{},
reservedNodesFns: map[string]api.ReservedNodesFn{},
victimTasksFns: map[string][]api.VictimTasksFn{},
jobStarvingFns: map[string]api.ValidateFn{},
}
snapshot := cache.Snapshot()
ssn.Jobs = snapshot.Jobs
for _, job := range ssn.Jobs {
if job.PodGroup != nil {
ssn.podGroupStatus[job.UID] = *job.PodGroup.Status.DeepCopy()
}
if vjr := ssn.JobValid(job); vjr != nil {
if !vjr.Pass {
jc := &scheduling.PodGroupCondition{
Type: scheduling.PodGroupUnschedulableType,
Status: v1.ConditionTrue,
LastTransitionTime: metav1.Now(),
TransitionID: string(ssn.UID),
Reason: vjr.Reason,
Message: vjr.Message,
}
if err := ssn.UpdatePodGroupCondition(job, jc); err != nil {
klog.Errorf("Failed to update job condition: %v", err)
}
}
delete(ssn.Jobs, job.UID)
}
}
ssn.NodeList = util.GetNodeList(snapshot.Nodes, snapshot.NodeList)
ssn.Nodes = snapshot.Nodes
ssn.CSINodesStatus = snapshot.CSINodesStatus
ssn.RevocableNodes = snapshot.RevocableNodes
ssn.Queues = snapshot.Queues
ssn.NamespaceInfo = snapshot.NamespaceInfo
// calculate all nodes' resource only once in each schedule cycle, other plugins can clone it when need
for _, n := range ssn.Nodes {
ssn.TotalResource.Add(n.Allocatable)
}
klog.V(3).Infof("Open Session %v with <%d> Job and <%d> Queues",
ssn.UID, len(ssn.Jobs), len(ssn.Queues))
return ssn
}缓存的设计应该是每一轮调度都用客户端去从apiserver拿资源的话压力太大了,通过scheduler里面的cache保存着,然后每一个调度周期新产生的session从这个cache拿就可以。
从缓存得到了session后,开始遍历schedulerconf里面配置的plugin,通过调用plugin的OnSessionOpen函数,注册入session中:
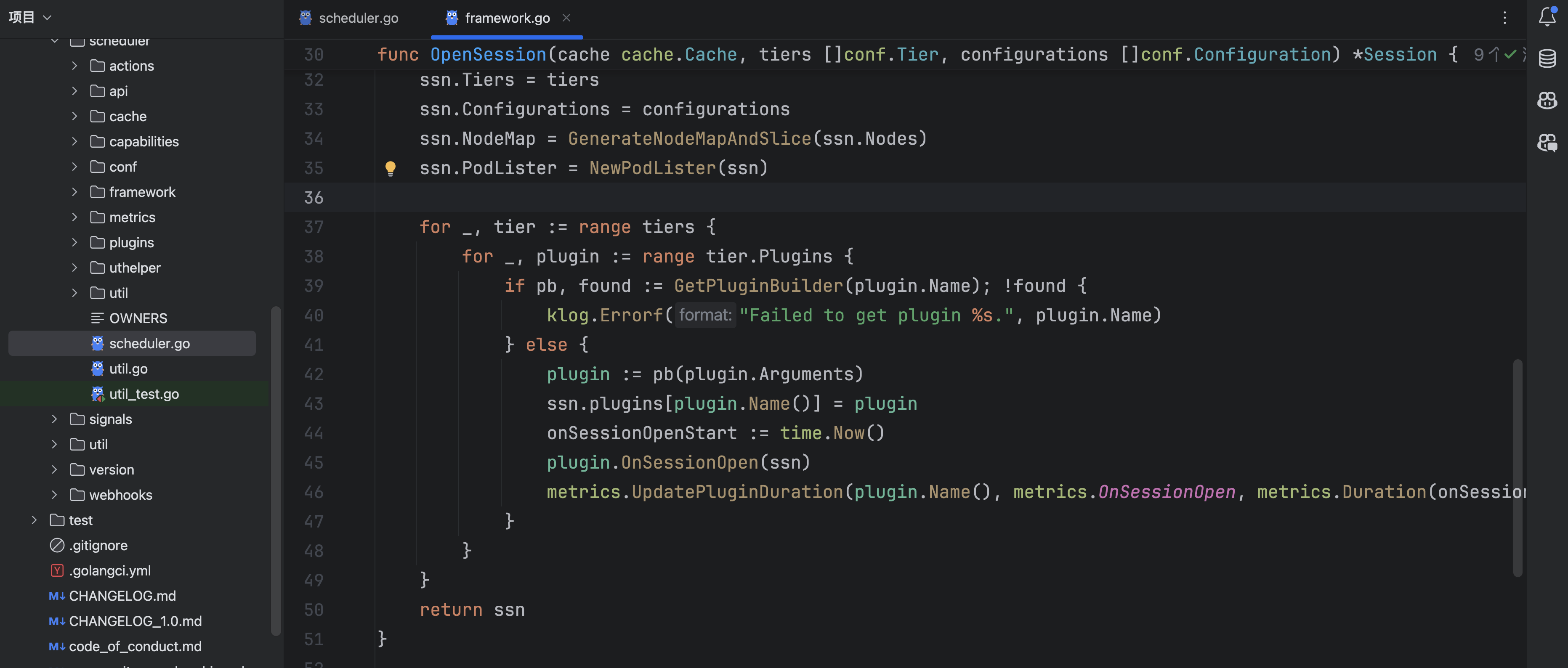
这里以一个overcommit插件为例:
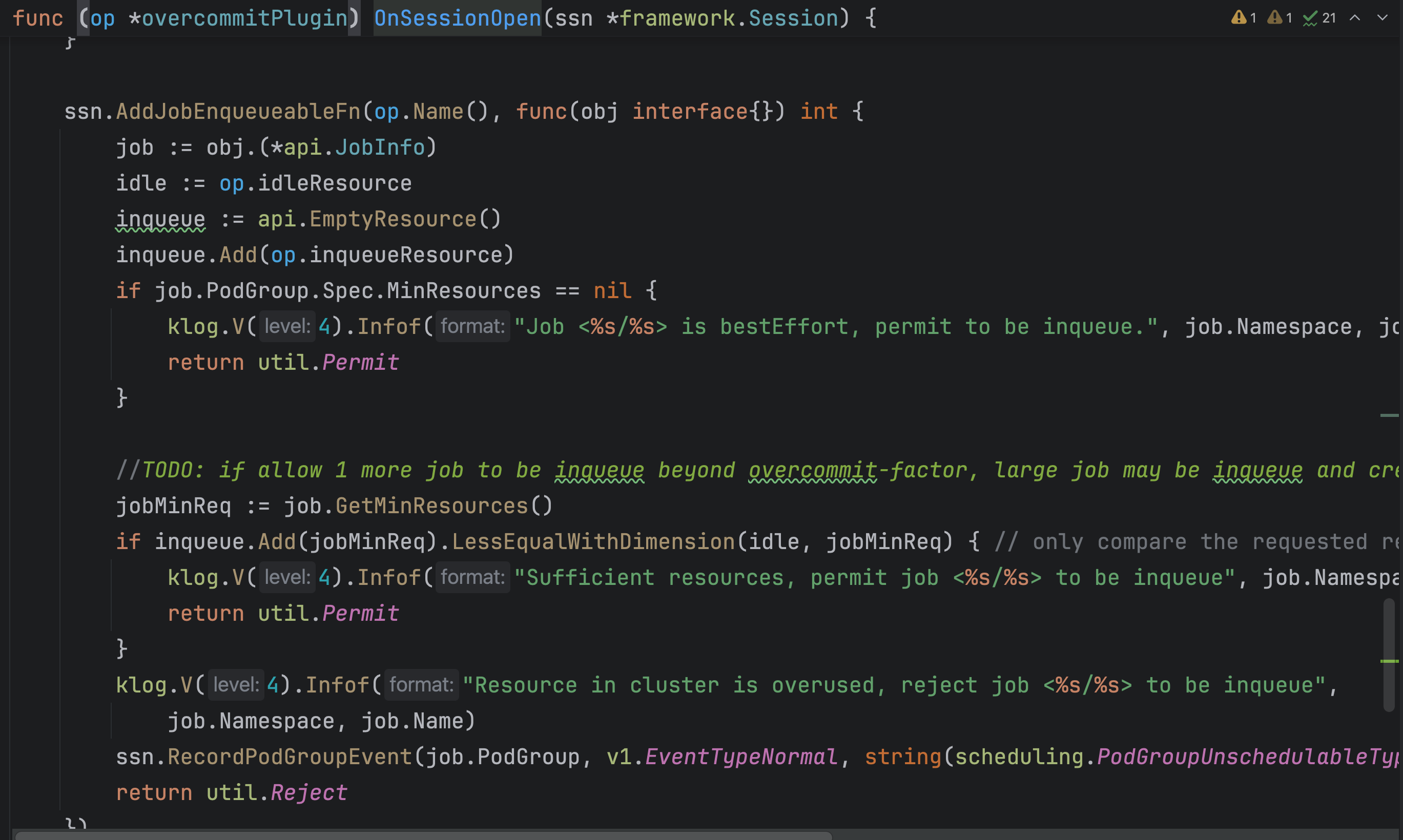
发现将一个function注册到session里面了,通过这个插件的名字就可以找到这个函数。
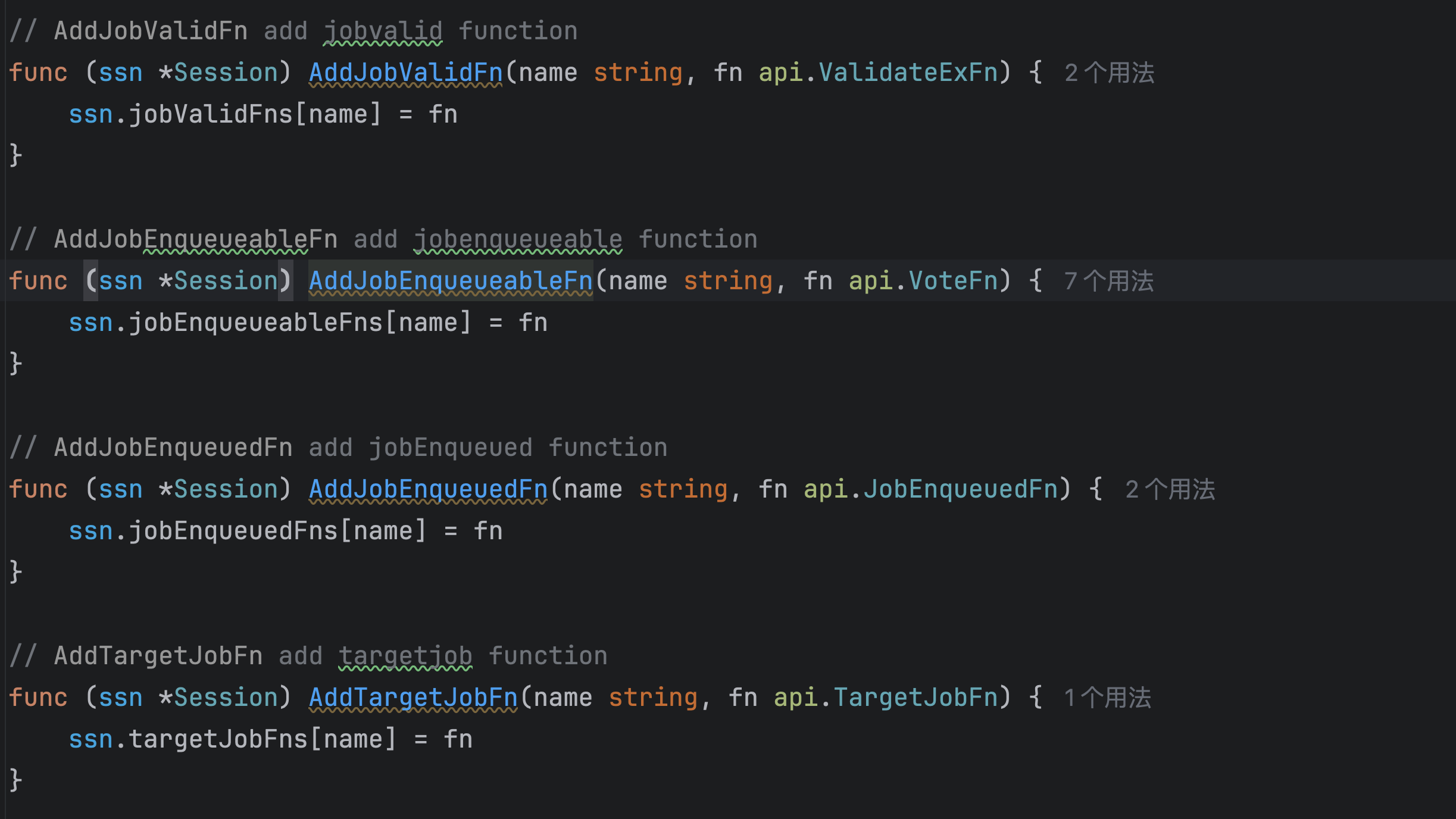
这里发现有很多的AddFn方法,把很多函数注册到session中的各种map了,具体看下session里面的fn map:
任务/作业排序
jobOrderFns: 比较两个作业的优先级,决定调度顺序(例如:优先级高的作业先调度)。queueOrderFns: 确定队列之间的调度顺序(例如:资源充足的队列优先)。taskOrderFns: 同一作业中多个任务的执行顺序(例如:按依赖关系排序)。
节点选择与排序
nodeOrderFns: 为节点打分,决定任务调度到哪个节点(例如:资源充足的节点分数更高)。batchNodeOrderFns: 批量节点排序,适用于需要同时考虑多个节点的场景。bestNodeFns: 在候选节点中选择最优节点(例如:综合考虑资源碎片和负载)。
调度过滤与验证
predicateFns: 检查任务是否满足节点条件(如资源需求、亲和性)。prePredicateFns: 在预选阶段前的预处理(例如:过滤掉某些节点)。overusedFns: 验证队列或集群是否超出资源限制(过载保护)。
抢占与回收
preemptableFns: 判断任务是否可被抢占(例如:低优先级任务可被高优先级抢占)。reclaimableFns: 判断队列是否可回收资源(例如:归还借用的资源)。victimTasksFns: 选择需要被驱逐的任务以腾出资源。
资源分配与预留
allocatableFns: 计算节点可分配资源(例如:考虑预留资源后的实际可用量)。reservedNodesFns: 处理节点预留逻辑(例如:为系统任务保留节点)。
作业状态管理
jobReadyFns: 检查作业是否满足调度条件(如依赖项已完成)。jobValidFns: 验证作业是否有效(例如:配置是否正确)。jobEnqueueableFns: 投票决定作业是否能进入调度队列。
其他扩展
clusterOrderFns: 多集群调度时比较集群优先级。nodeMapFns/nodeReduceFns: 转换或合并节点信息。jobStarvingFns: 判断作业是否因资源不足而处于饥饿状态。
至此,通过plugin的OnSessionOpen方法,就把各种插件中包含的多个函数注册到session里面了。
一个插件会包含多个函数,会逐步注册
等所有的plugin注册都调用OnSessionOpen注册后,调度器的OpenSession阶段就结束了。
继续看runOnce:
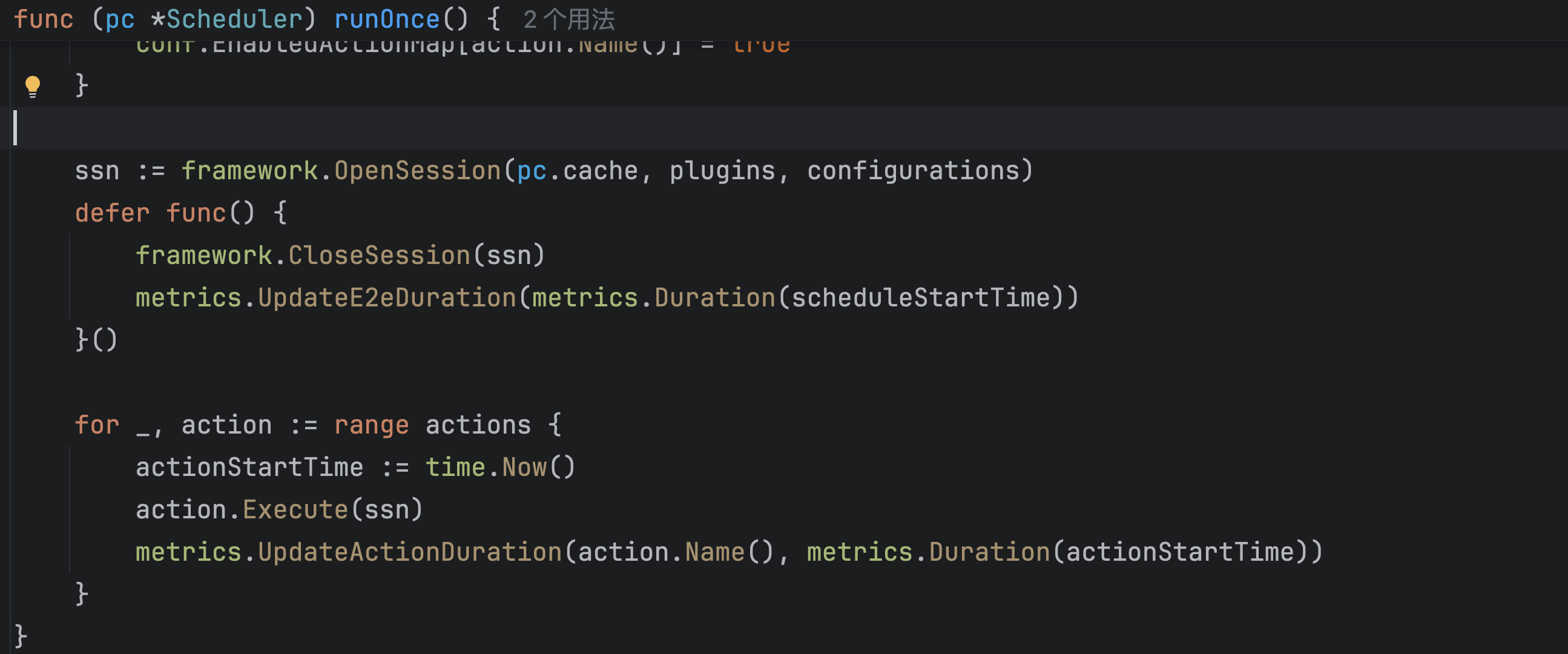
注册好plugin后,开始遍历action了,对于每一个action都会调用Execute,等所有的action都执行后,这一次的调度就结束了。
2、Enqueue
第一个action就是必须要有的enqueue:
根据官方的介绍:
Enqueue action筛选符合要求的作业进入待调度队列。当一个Job下的最小资源申请量不能得到满足时,即使为Job下的Pod执行调度动作,Pod也会因为gang约束没有达到而无法进行调度。只有当集群资源满足作业声明的最小资源需求时,Enqueue action才允许该作业入队,使得PodGroup的状态由Pending状态转换为Inqueue状态。这个状态转换是Pod创建的前提,只有PodGroup进入Inqueue状态后,vc-controller才会为该PodGroup创建Pod。这种机制确保了Pod只会在资源满足的情况下被创建,是调度器配置中必不可少的action。
嗯,大概意思就是筛选符合的job进入待调度队列,并且将podgroup的状态变成inqueue:
func (enqueue *Action) Execute(ssn *framework.Session) {
klog.V(5).Infof("Enter Enqueue ...")
defer klog.V(5).Infof("Leaving Enqueue ...")
queues := util.NewPriorityQueue(ssn.QueueOrderFn)
queueSet := sets.NewString()
jobsMap := map[api.QueueID]*util.PriorityQueue{}
for _, job := range ssn.Jobs {
if job.ScheduleStartTimestamp.IsZero() {
ssn.Jobs[job.UID].ScheduleStartTimestamp = metav1.Time{
Time: time.Now(),
}
}
if queue, found := ssn.Queues[job.Queue]; !found {
klog.Errorf("Failed to find Queue <%s> for Job <%s/%s>",
job.Queue, job.Namespace, job.Name)
continue
} else if !queueSet.Has(string(queue.UID)) {
klog.V(5).Infof("Added Queue <%s> for Job <%s/%s>",
queue.Name, job.Namespace, job.Name)
queueSet.Insert(string(queue.UID))
queues.Push(queue)
}
if job.IsPending() {
if _, found := jobsMap[job.Queue]; !found {
jobsMap[job.Queue] = util.NewPriorityQueue(ssn.JobOrderFn)
}
klog.V(5).Infof("Added Job <%s/%s> into Queue <%s>", job.Namespace, job.Name, job.Queue)
jobsMap[job.Queue].Push(job)
}
}
klog.V(3).Infof("Try to enqueue PodGroup to %d Queues", len(jobsMap))
for {
if queues.Empty() {
break
}
queue := queues.Pop().(*api.QueueInfo)
// skip the Queue that has no pending job
jobs, found := jobsMap[queue.UID]
if !found || jobs.Empty() {
continue
}
job := jobs.Pop().(*api.JobInfo)
if job.PodGroup.Spec.MinResources == nil || ssn.JobEnqueueable(job) {
ssn.JobEnqueued(job)
job.PodGroup.Status.Phase = scheduling.PodGroupInqueue
ssn.Jobs[job.UID] = job
}
// Added Queue back until no job in Queue.
queues.Push(queue)
}
}前半部分在构建优先队列:首先获取这次session中需要调度的jobs,将job对应的queue加入优先队列中,再将job放入job对应的queue中。
这么做的原因是可以优先处理具有高优先级的queue,先处理高优先级queue中的高优先级job,然后处理高优先级queue的低优先级job,然后再处理低优先级queue里面的job。(即一次分类)
后半部分是for循环,直到queue中所有的job都被处理了,才结束。具体处理的过程是:从优先队列里面弹出一个queue,再从这个queue中弹出一个job,也就是最高优先级的job,然后执行JobEnqueued:
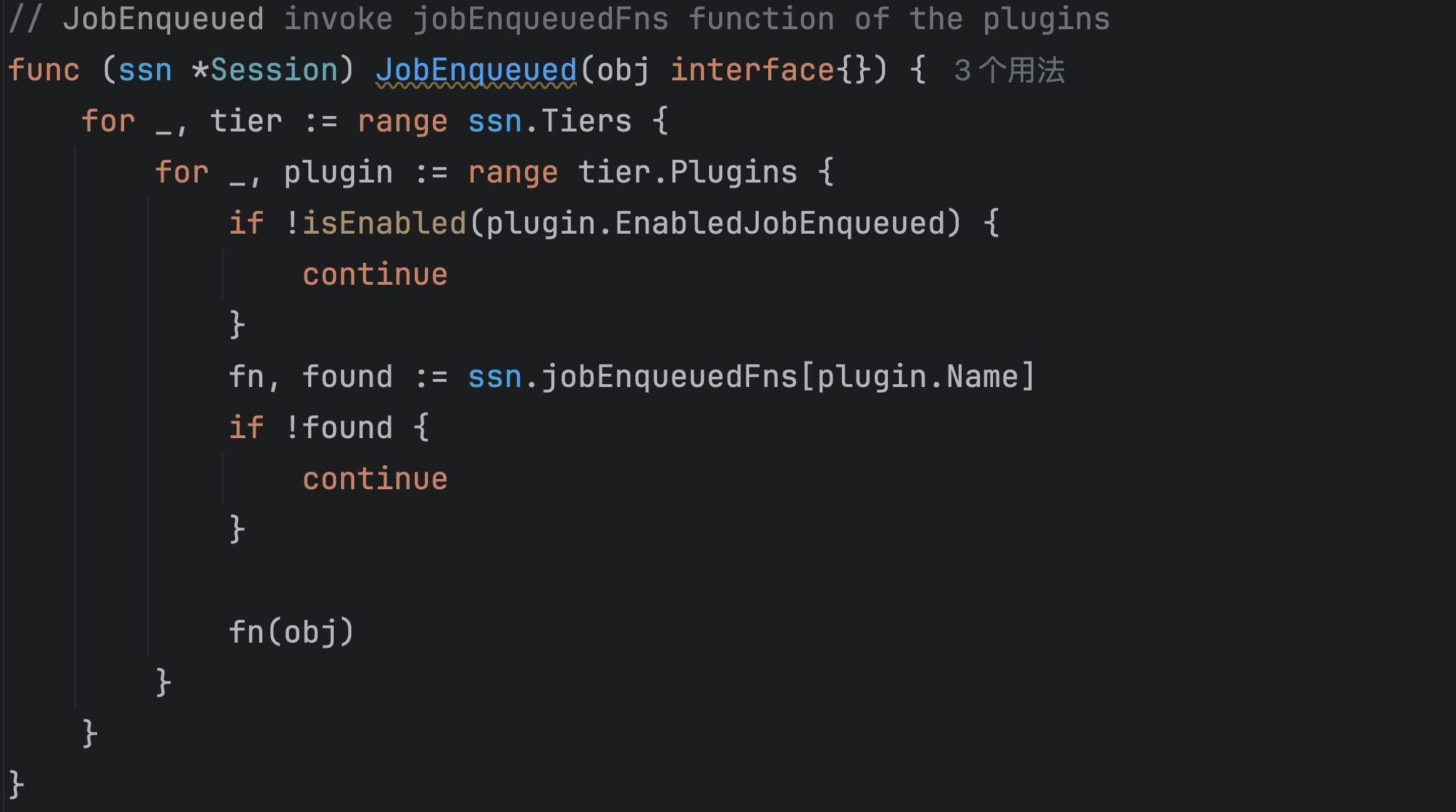
在这里面遍历所有的plugin,看是否有plugin是在enqueue阶段执行的,如果有,就找到这个插件对应的函数执行。
刚才在OpenSession阶段,遍历了所有的plugin,将plugin中涉及的function都注册到session了,这里就是具体的调用。
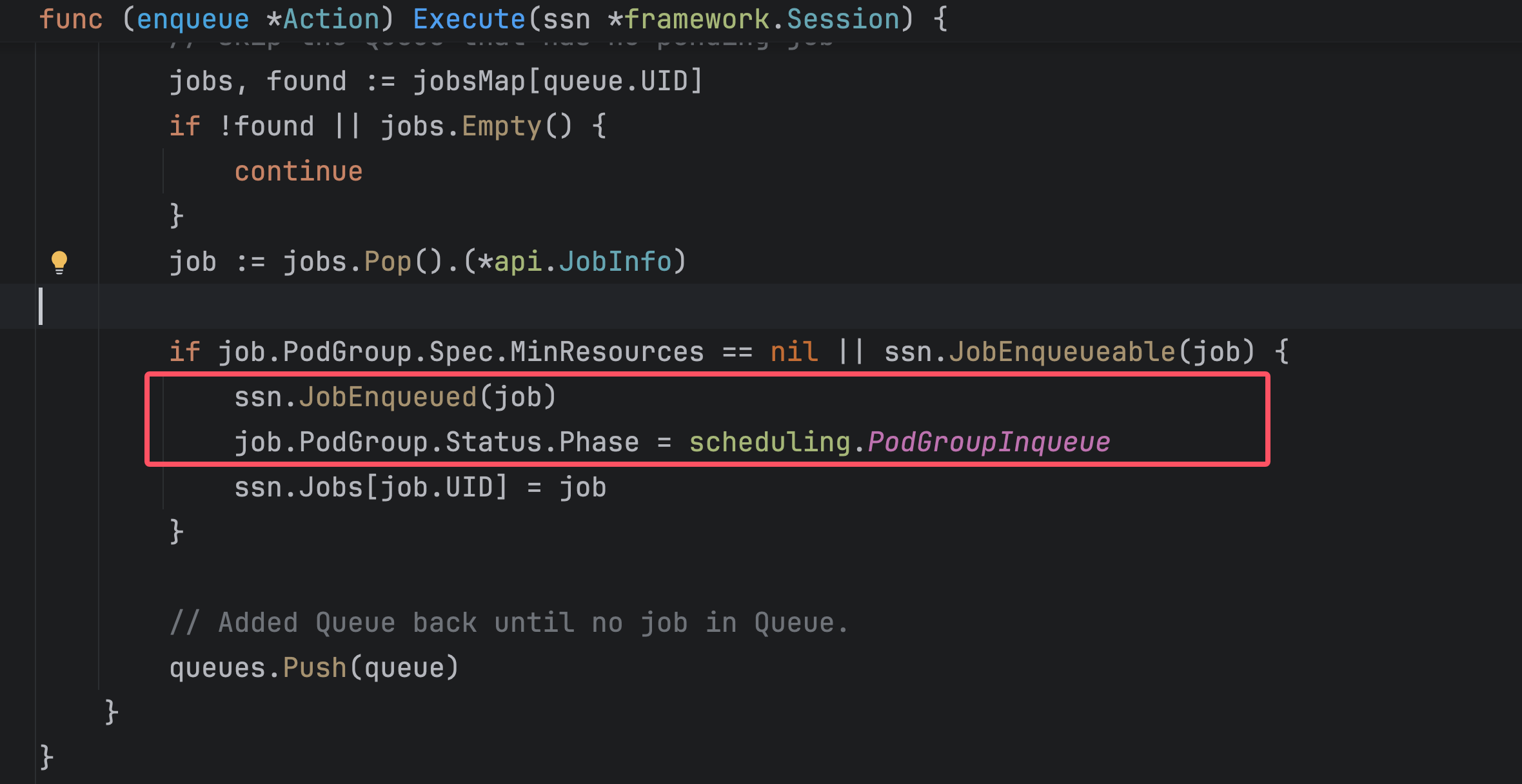
等这个action阶段对应plugin的函数执行完成后,再更改podgroup的状态,变成inqueue,这个阶段就结束了。
3、allocate
enqueue阶段只是做了预处理,并没有执行调度逻辑,接下来的allocate才是关键:
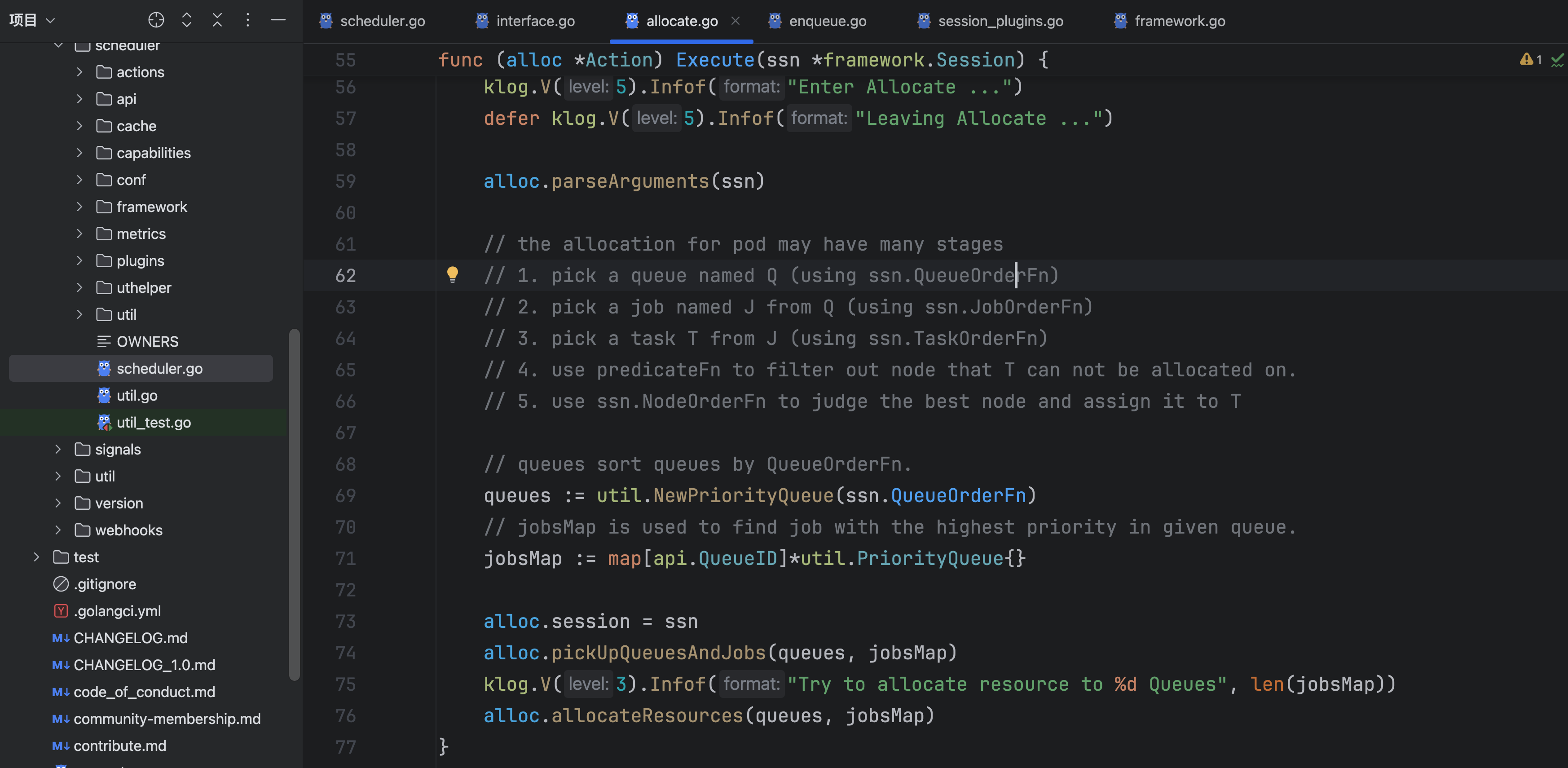
根据这个注释发现处理的逻辑是:先挑选一个queue,再从这个queue里选出一个job,再从这个job里选出一个task进行调度。
pickUpQueuesAndJobs这个函数会遍历所有的job、取出pending的job、验证作业有效性,接下来就按照job对应的queue进行分类,将属于一个queue的job放到一起。这样就构建好了queue和这个queue对应的jobs了。
func (alloc *Action) pickUpQueuesAndJobs(queues *util.PriorityQueue, jobsMap map[api.QueueID]*util.PriorityQueue) {
ssn := alloc.session
for _, job := range ssn.Jobs {
// If not config enqueue action, change Pending pg into Inqueue state to avoid blocking job scheduling.
if job.IsPending() {
if conf.EnabledActionMap["enqueue"] {
klog.V(4).Infof("Job <%s/%s> Queue <%s> skip allocate, reason: job status is pending.",
job.Namespace, job.Name, job.Queue)
continue
} else {
klog.V(4).Infof("Job <%s/%s> Queue <%s> status update from pending to inqueue, reason: no enqueue action is configured.",
job.Namespace, job.Name, job.Queue)
job.PodGroup.Status.Phase = scheduling.PodGroupInqueue
}
}
if vr := ssn.JobValid(job); vr != nil && !vr.Pass {
klog.V(4).Infof("Job <%s/%s> Queue <%s> skip allocate, reason: %v, message %v", job.Namespace, job.Name, job.Queue, vr.Reason, vr.Message)
continue
}
if _, found := ssn.Queues[job.Queue]; !found {
klog.Warningf("Skip adding Job <%s/%s> because its queue %s is not found",
job.Namespace, job.Name, job.Queue)
continue
}
if _, found := jobsMap[job.Queue]; !found {
jobsMap[job.Queue] = util.NewPriorityQueue(ssn.JobOrderFn)
queues.Push(ssn.Queues[job.Queue])
}
klog.V(4).Infof("Added Job <%s/%s> into Queue <%s>", job.Namespace, job.Name, job.Queue)
jobsMap[job.Queue].Push(job)
}
}allocateResources 通过for循环一直处理待调度队列中的job,对job调用allocateResourcesForTasks
// allocateResources primarily accomplishes two steps:
// 1. picks up tasks.
// 2. allocates resources to these tasks. (this step is carried out by the allocateResourcesForTasks method.)
func (alloc *Action) allocateResources(queues *util.PriorityQueue, jobsMap map[api.QueueID]*util.PriorityQueue) {
ssn := alloc.session
pendingTasks := map[api.JobID]*util.PriorityQueue{}
allNodes := ssn.NodeList
// To pick <namespace, queue> tuple for job, we choose to pick namespace firstly.
// Because we believe that number of queues would less than namespaces in most case.
// And, this action would make the resource usage among namespace balanced.
for {
if queues.Empty() {
break
}
queue := queues.Pop().(*api.QueueInfo)
if ssn.Overused(queue) {
klog.V(3).Infof("Queue <%s> is overused, ignore it.", queue.Name)
continue
}
klog.V(3).Infof("Try to allocate resource to Jobs in Queue <%s>", queue.Name)
jobs, found := jobsMap[queue.UID]
if !found || jobs.Empty() {
klog.V(4).Infof("Can not find jobs for queue %s.", queue.Name)
continue
}
job := jobs.Pop().(*api.JobInfo)
if _, found = pendingTasks[job.UID]; !found {
tasks := util.NewPriorityQueue(ssn.TaskOrderFn)
for _, task := range job.TaskStatusIndex[api.Pending] {
// Skip tasks whose pod are scheduling gated
if task.SchGated {
continue
}
// Skip BestEffort task in 'allocate' action.
if task.Resreq.IsEmpty() {
klog.V(4).Infof("Task <%v/%v> is BestEffort task, skip it.",
task.Namespace, task.Name)
continue
}
tasks.Push(task)
}
pendingTasks[job.UID] = tasks
}
tasks := pendingTasks[job.UID]
if tasks.Empty() {
// put queue back again and try other jobs in this queue
queues.Push(queue)
continue
}
klog.V(3).Infof("Try to allocate resource to %d tasks of Job <%v/%v>",
tasks.Len(), job.Namespace, job.Name)
alloc.allocateResourcesForTasks(tasks, job, jobs, queue, allNodes)
// Put back the queue to priority queue after job's resource allocating finished,
// To ensure that the priority of the queue is calculated based on the latest resource allocation situation.
queues.Push(queue)
}
}allocateResourcesForTasks对单个job进行处理,一个job就是一个podgroup,里面会包含多个pod,pod就是task,那么tasks就是job了。通过for循环,遍历这个job里面的每一个task,为每一个task找到合适的node,进行绑定,至此就完成了调度。
func (alloc *Action) allocateResourcesForTasks(tasks *util.PriorityQueue, job *api.JobInfo, jobs *util.PriorityQueue, queue *api.QueueInfo, allNodes []*api.NodeInfo) {
ssn := alloc.session
stmt := framework.NewStatement(ssn)
ph := util.NewPredicateHelper()
for !tasks.Empty() {
task := tasks.Pop().(*api.TaskInfo)
if !ssn.Allocatable(queue, task) {
klog.V(3).Infof("Queue <%s> is overused when considering task <%s>, ignore it.", queue.Name, task.Name)
continue
}
// check if the task with its spec has already predicates failed
if job.TaskHasFitErrors(task) {
klog.V(5).Infof("Task %s with role spec %s has already predicated failed, skip", task.Name, task.TaskRole)
continue
}
klog.V(3).Infof("There are <%d> nodes for Job <%v/%v>", len(ssn.Nodes), job.Namespace, job.Name)
if err := ssn.PrePredicateFn(task); err != nil {
klog.V(3).Infof("PrePredicate for task %s/%s failed for: %v", task.Namespace, task.Name, err)
fitErrors := api.NewFitErrors()
for _, ni := range allNodes {
fitErrors.SetNodeError(ni.Name, err)
}
job.NodesFitErrors[task.UID] = fitErrors
break
}
predicateNodes, fitErrors := ph.PredicateNodes(task, allNodes, alloc.predicate, alloc.enablePredicateErrorCache)
if len(predicateNodes) == 0 {
job.NodesFitErrors[task.UID] = fitErrors
// Assume that all left tasks are allocatable, but can not meet gang-scheduling min member,
// so we should break from continuously allocating.
// otherwise, should continue to find other allocatable task
if job.NeedContinueAllocating() {
continue
} else {
break
}
}
// Candidate nodes are divided into two gradients:
// - the first gradient node: a list of free nodes that satisfy the task resource request;
// - The second gradient node: the node list whose sum of node idle resources and future idle meets the task resource request;
// Score the first gradient node first. If the first gradient node meets the requirements, ignore the second gradient node list,
// otherwise, score the second gradient node and select the appropriate node.
var candidateNodes [][]*api.NodeInfo
var idleCandidateNodes []*api.NodeInfo
var futureIdleCandidateNodes []*api.NodeInfo
for _, n := range predicateNodes {
if task.InitResreq.LessEqual(n.Idle, api.Zero) {
idleCandidateNodes = append(idleCandidateNodes, n)
} else if task.InitResreq.LessEqual(n.FutureIdle(), api.Zero) {
futureIdleCandidateNodes = append(futureIdleCandidateNodes, n)
} else {
klog.V(5).Infof("Predicate filtered node %v, idle: %v and future idle: %v do not meet the requirements of task: %v",
n.Name, n.Idle, n.FutureIdle(), task.Name)
}
}
candidateNodes = append(candidateNodes, idleCandidateNodes)
candidateNodes = append(candidateNodes, futureIdleCandidateNodes)
var bestNode *api.NodeInfo
for index, nodes := range candidateNodes {
if klog.V(5).Enabled() {
for _, node := range nodes {
klog.V(5).Infof("node %v, idle: %v, future idle: %v", node.Name, node.Idle, node.FutureIdle())
}
}
switch {
case len(nodes) == 0:
klog.V(5).Infof("Task: %v, no matching node is found in the candidateNodes(index: %d) list.", task.Name, index)
case len(nodes) == 1: // If only one node after predicate, just use it.
bestNode = nodes[0]
case len(nodes) > 1: // If more than one node after predicate, using "the best" one
nodeScores := util.PrioritizeNodes(task, nodes, ssn.BatchNodeOrderFn, ssn.NodeOrderMapFn, ssn.NodeOrderReduceFn)
bestNode = ssn.BestNodeFn(task, nodeScores)
if bestNode == nil {
bestNode = util.SelectBestNode(nodeScores)
}
}
// If a proper node is found in idleCandidateNodes, skip futureIdleCandidateNodes and directly return the node information.
if bestNode != nil {
break
}
}
// Allocate idle resource to the task.
if task.InitResreq.LessEqual(bestNode.Idle, api.Zero) {
klog.V(3).Infof("Binding Task <%v/%v> to node <%v>", task.Namespace, task.Name, bestNode.Name)
if err := stmt.Allocate(task, bestNode); err != nil {
klog.Errorf("Failed to bind Task %v on %v in Session %v, err: %v",
task.UID, bestNode.Name, ssn.UID, err)
if rollbackErr := stmt.UnAllocate(task); rollbackErr != nil {
klog.Errorf("Failed to unallocate Task %v on %v in Session %v for %v.",
task.UID, bestNode.Name, ssn.UID, rollbackErr)
}
} else {
metrics.UpdateE2eSchedulingDurationByJob(job.Name, string(job.Queue), job.Namespace, metrics.Duration(job.CreationTimestamp.Time))
metrics.UpdateE2eSchedulingLastTimeByJob(job.Name, string(job.Queue), job.Namespace, time.Now())
}
} else {
klog.V(3).Infof("Predicates failed in allocate for task <%s/%s> on node <%s> with limited resources",
task.Namespace, task.Name, bestNode.Name)
// Allocate releasing resource to the task if any.
if task.InitResreq.LessEqual(bestNode.FutureIdle(), api.Zero) {
klog.V(3).Infof("Pipelining Task <%v/%v> to node <%v> for <%v> on <%v>",
task.Namespace, task.Name, bestNode.Name, task.InitResreq, bestNode.Releasing)
if err := stmt.Pipeline(task, bestNode.Name, false); err != nil {
klog.Errorf("Failed to pipeline Task %v on %v in Session %v for %v.",
task.UID, bestNode.Name, ssn.UID, err)
if rollbackErr := stmt.UnPipeline(task); rollbackErr != nil {
klog.Errorf("Failed to unpipeline Task %v on %v in Session %v for %v.",
task.UID, bestNode.Name, ssn.UID, rollbackErr)
}
} else {
metrics.UpdateE2eSchedulingDurationByJob(job.Name, string(job.Queue), job.Namespace, metrics.Duration(job.CreationTimestamp.Time))
metrics.UpdateE2eSchedulingLastTimeByJob(job.Name, string(job.Queue), job.Namespace, time.Now())
}
}
}
if ssn.JobReady(job) && !tasks.Empty() {
jobs.Push(job)
break
}
}
if ssn.JobReady(job) {
stmt.Commit()
} else {
if !ssn.JobPipelined(job) {
stmt.Discard()
}
}
}具体的调度策略执行是通过predicateFn的,在这个函数里面,会检查plugin是否属于这个阶段,如果是,就会执行这个plugin对应的函数。
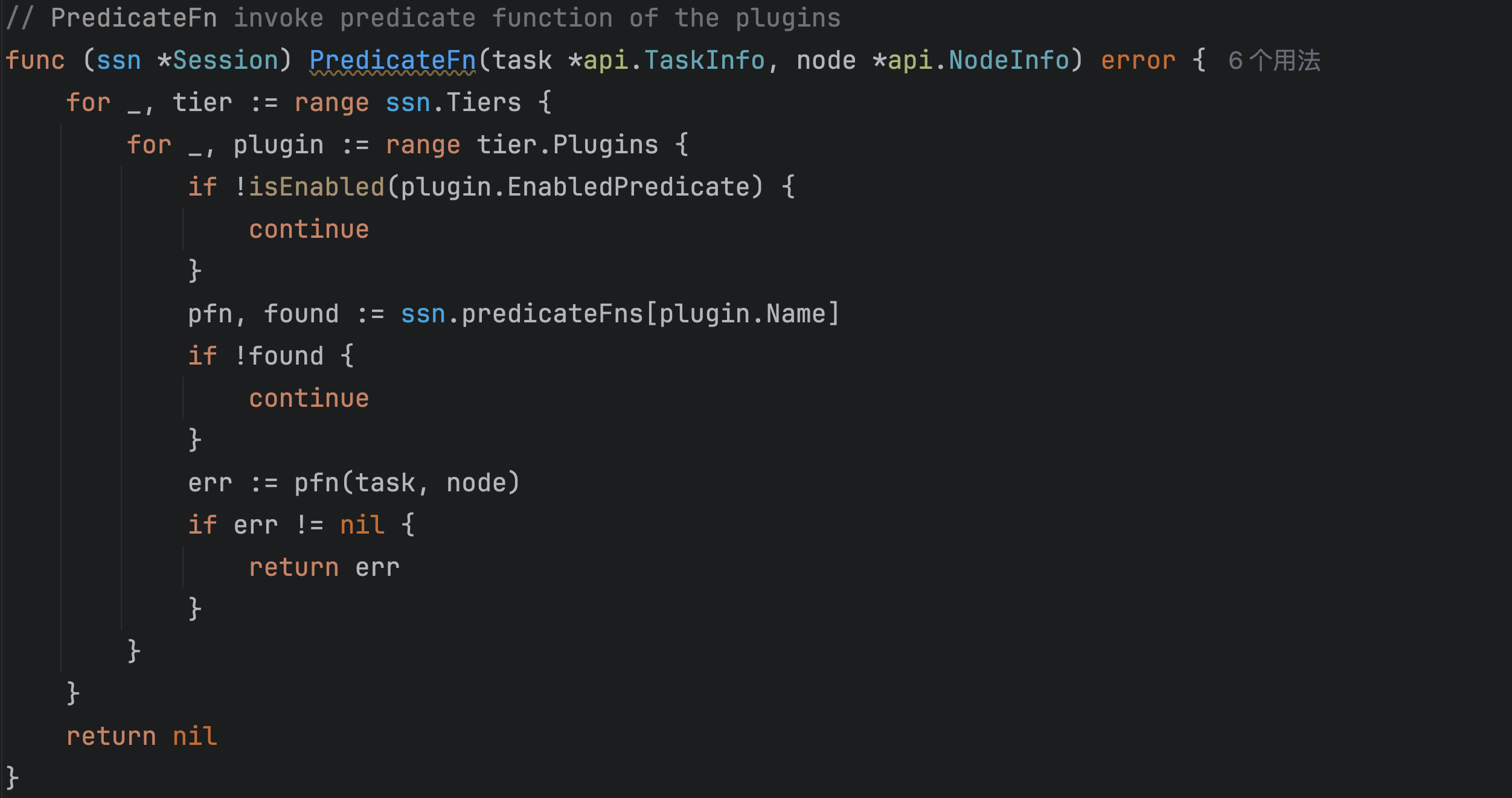
发现这些plugin里面都有这个阶段的函数,都会影响predicate。
4、总结
通过这两个action的分析,已经可以看出来整个调度器的处理逻辑了。
(1)New一个scheduler,然后启动。
(2)启动的调度器每隔一个调度周期就会进行一次调度循环,调度循环的开始是OpenSession阶段。
(3)在OpenSession阶段,会根据缓存中的信息获取到session对象,在这个session中就会保存着已有的queue和plugin、action等全局配置。
(4)遍历配置的plugin,调用plugin的OnSessionOpen函数,在这个函数中会把插件对应的函数注册到session对象中。
(5)等所有的plugin都注册完成后,遍历action,对于每一个action都会调用Execute。
(6)对一个action执行Execute,就会执行这一个action包含的plugin对应的函数,也就是调用上一步注册的函数。
(7)等所有的action的plugin对应函数都执行完成后,这一次调度循环就结束了,等待一个调度周期后开始下一次循环。
现在来看这个图就很清晰了,OpenSession注册plugin对应的function,接下来的action执行function。
在每个action中,会在固定的地方执行function,这个function就是由各plugin中注册的扩展点。
一个action中会有多个function
一个function会有多个plugin注册的函数,即大function会执行多个小function。大function在action的固定位置执行,小function由plugin提供。
5、action、plugin、扩展点
扩展点:
QueueOrderFn 用于排序
Queue资源jobOrderFn 用于排序
Job资源JobEnqueueable 用于判断
Job是否可以被调度JobEnqueued 用于标记
Job已经开始调度TaskOrderFn 用于排序
Task资源JobValid 判断
job是否可以进行分配PredicateFn 判断
node是否满足task的运行需求Overused 判断
queue是否超出资源限制Allocatable 判断指定
queue是否可以对task进行分配PrePredicateFn 判断
task是否可以进行分配BatchNodeOrderFn 不同维度对
node评分NodeOrderMapFn 不同维度对
node评分NodeOrderReduceFn 不同维度对
node评分JobReady 判断
job是否可以执行分配动作JobPipelined 判断
job是否在排序等待资源中JobStarving 判断
job是否需要更多资源Preemptable 返回可以被抢占的受害者
task列表VictimTasks 获取需要驱逐的
taskReclaimable 获取可以被回收的task

