

六、Hyperparameter Tuning and Auto ML
在前几章中,我们已经看到Kubeflow如何帮助机器学习的各个阶段。但是,了解每个阶段该做什么——无论是特征准备、训练还是模型部署——都需要一定的专业知识和实验。根据“没有免费午餐”定理,没有一个模型能够适用于所有的机器学习问题,因此每个模型都必须精心构建。如果每个阶段都需要大量的人工投入,那么完全构建一个高性能模型可能会非常耗时且成本高昂。
自然而然地,人们可能会想:是否有可能自动化部分甚至整个机器学习过程?我们能否在保持高质量模型的同时,减少数据科学家的工作量?
在机器学习中,解决这类问题的总称是自动化机器学习(AutoML)。这是一个不断发展的研究领域,并已在工业中找到了实际应用。AutoML旨在通过减少在机器学习中耗时且迭代的阶段(如特征工程、模型构建和超参数配置)中的人工干预,从而为专家和非专家简化机器学习流程。
在本章中,我们将探讨如何使用Kubeflow自动化超参数搜索和神经架构搜索,这是AutoML的两个重要子领域。
1、AutoML:概述
AutoML 指的是自动化机器学习过程中部分环节的各种流程和工具。从高层次来看,AutoML 是指任何旨在解决以下一个或多个问题的算法和方法论:
数据预处理
机器学习需要数据,而原始数据可能来自各种来源并以不同格式存在。为了使原始数据可用,人类专家通常需要梳理数据、规范化数值、删除错误或损坏的数据,并确保数据的一致性。
特征工程
使用过少的输入变量(或“特征”)训练模型可能导致模型不准确。然而,特征过多也会带来问题;学习过程会变得更慢且更耗费资源,并可能出现过拟合问题。找到合适的特征集可能是构建机器学习模型中最耗时的部分。自动化特征工程可以加速特征提取、选择和转换的过程。
模型选择
一旦获得所有训练数据,您需要为数据集选择合适的训练模型。理想的模型应尽可能简单,同时仍能提供良好的预测准确性。
超参数调优
大多数学习模型都有一些与模型外部相关的参数,例如学习率、批量大小和神经网络中的层数。我们称这些为超参数,以区别于学习过程中调整的模型参数。超参数调优是自动化搜索这些参数以提高模型准确性的过程。
神经架构搜索
与超参数调优相关的一个领域是神经架构搜索(NAS)。与为每个超参数值选择固定范围的值不同,NAS 旨在将自动化更进一步,生成一个优于手工设计架构的完整神经网络。NAS 的常见方法包括强化学习和进化算法。
2、使用Kubeflow Katib进行超参数调优
在机器学习中,超参数指的是在训练过程开始之前设置的参数(与从训练过程中学习的模型参数相对)。超参数的例子包括学习率、决策树的数量、神经网络中的层数等。
超参数优化的概念非常简单:选择能够使模型性能最优的超参数值集合。超参数调优框架正是实现这一目标的工具。通常,此类工具的用户需要定义以下几项内容:
超参数列表及其有效取值范围(称为搜索空间)
用于衡量模型性能的指标
搜索过程中使用的方法论
Kubeflow 内置了 Katib,这是一个用于超参数调优的通用框架。在类似的开源工具中,Katib 具有以下几个显著特点:
Kubernetes 原生
这意味着 Katib 实验可以在任何运行 Kubernetes 的环境中移植。
多框架支持
Katib 支持许多流行的学习框架,并对 TensorFlow 和 PyTorch 的分布式训练提供一流支持。
语言无关性
训练代码可以用任何语言编写,只要将其构建为 Docker 镜像即可。
2.1、Katib概念
让我们首先定义几个对Katib工作流程至关重要的术语(如图10-1所示):
Experiment
实验是一个端到端的过程,它接受一个问题(例如,为手写识别调整训练模型)、一个目标指标(最大化预测准确率)和一个搜索空间(超参数的范围),并生成一组最终的最优超参数值。
Suggestion
建议是我们试图解决的问题的一种可能解决方案。由于我们试图找到能带来最优模型性能的超参数值组合,因此建议是指从指定的搜索空间中选择的一组超参数值。
Trial
trial是experiment的一次迭代。每次trial接受一个suggestion,并执行一个工作进程(通过Docker打包),该进程生成评估指标。然后,Katib的控制器根据先前的指标计算下一个suggestion,并生成新的trials。
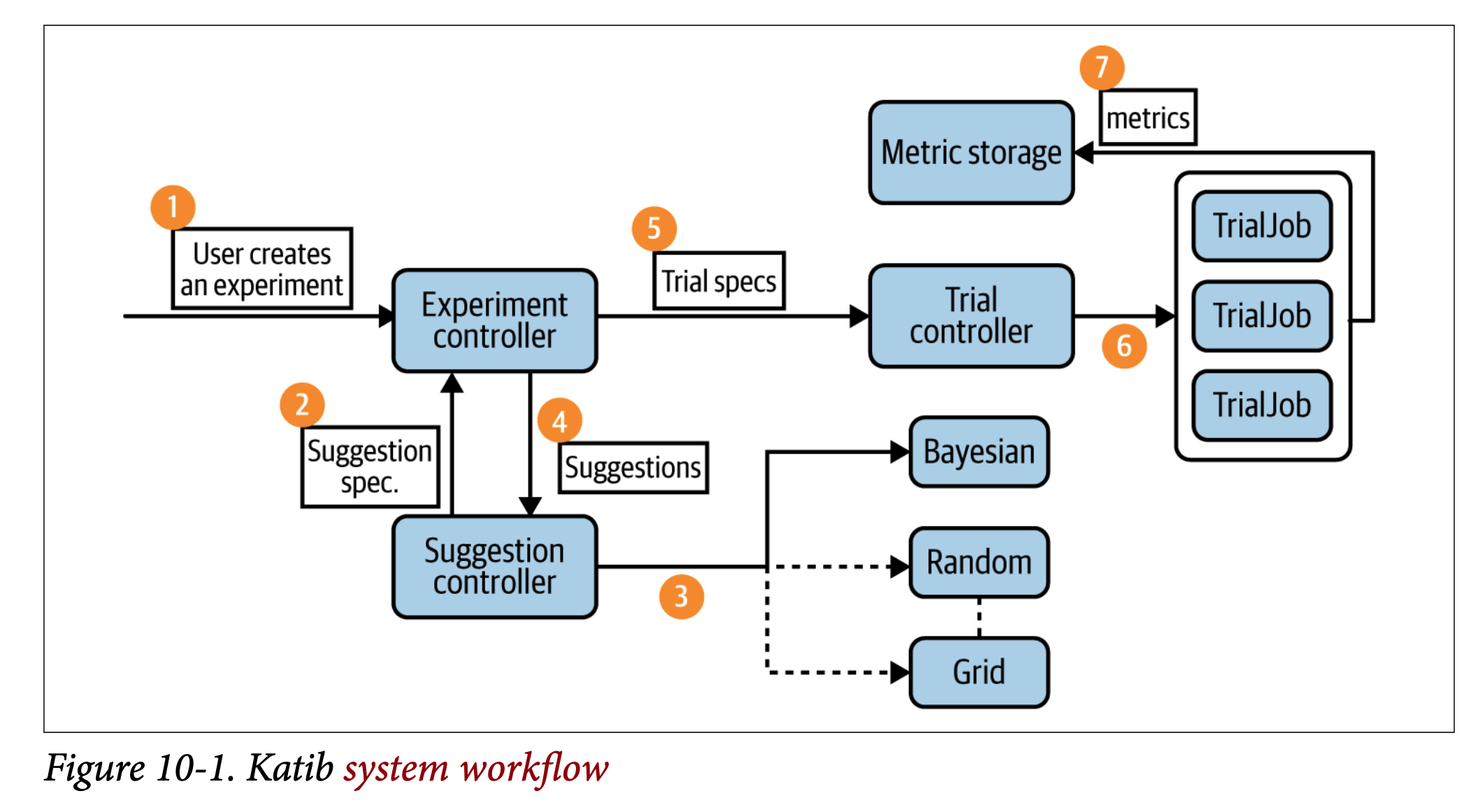
在Katib中,实验、建议和试验都是自定义资源。这意味着它们存储在Kubernetes中,并且可以使用标准的Kubernetes API进行操作。
超参数调优的另一个重要方面是如何找到下一组参数。截至本文撰写时,Katib支持以下搜索算法:
网格搜索
也称为参数扫描,网格搜索是最简单的方法——在指定的搜索空间中穷举所有可能的参数值。尽管资源密集,但网格搜索具有高度并行化的优势,因为任务完全独立。
随机搜索
与网格搜索类似,随机搜索中的任务也是完全独立的。与枚举所有可能值不同,随机搜索通过随机选择生成参数值。当需要调优的超参数较多(但只有少数对模型性能有显著影响)时,随机搜索可以显著优于网格搜索。当离散参数数量较多时,随机搜索也非常有用,这使得网格搜索变得不可行。
贝叶斯优化
这是一种利用概率和统计学寻找更好参数的强大方法。贝叶斯优化为目标函数构建概率模型,找到在模型上表现良好的参数值,然后根据试验运行期间收集的指标迭代更新模型。直观地说,贝叶斯优化通过有根据的猜测来改进模型。这种优化方法依赖于之前的迭代来寻找新参数,并且可以并行化。虽然试验不如网格或随机搜索独立,但贝叶斯优化可以在总体上以更少的试验找到结果。
Hyperband
这是一种相对较新的方法,随机选择配置值。但与传统的随机搜索不同,Hyperband只对每个试验进行少量迭代评估。然后,它选择表现最好的配置并运行更长时间,重复此过程直到达到预期结果。由于其与随机搜索的相似性,任务可以高度并行化。
Katib拼图的最后一块是metrics collector。这是一个在每次试验后收集并解析评估指标,并将其推送到Katib持久化数据库中的过程。Katib通过一个边车容器实现指标收集,该容器与主容器在同一个Pod中并行运行。
总体而言,Katib的设计使其具有高度可扩展性、可移植性和可扩展性。由于它是Kubeflow平台的一部分,Katib原生支持与Kubeflow的其他训练组件(如TFJob和PyTorch operator)的集成。Katib也是第一个支持多租户的超参数调优框架,使其成为云托管环境的理想选择。
2.2、运行第一个Katib实验
在本节中,我们将使用Katib来调优一个简单的MNist模型。您可以在Katib的GitHub页面上找到源代码和所有配置文件。
第一步是准备您的训练代码。由于Katib运行训练作业以进行试验评估,每个训练作业需要打包为Docker容器。Katib是语言无关的,因此您如何编写训练代码并不重要。然而,为了与Katib兼容,训练代码必须满足几个要求:
超参数必须作为命令行参数公开。例如:
python mnist.py --batch_size=100 --learning_rate=0.1指标必须以与指标收集器一致的格式暴露。Katib 目前支持通过标准输出、文件、TensorFlow 事件或自定义方式收集指标。最简单的选项是使用标准指标收集器,这意味着评估指标必须以以下格式写入标准输出:
metrics_name=metrics_value我们将使用的示例训练模型代码可以在GitHub网站上找到。准备好训练代码后,只需将其打包为Docker镜像即可开始使用。
一旦你有了训练容器,下一步就是为你的实验编写规范。Katib 使用 Kubernetes 自定义资源来表示实验。示例 10-1 可以从这个 GitHub 页面下载。


Objective:此处用于配置如何衡量训练模型的性能以及实验的目标。在本实验中,我们的目标是最大化验证准确率指标。如果达到0.99(99%准确率)的目标值,我们将停止实验。additionalMetrics Names表示从每次试验中收集的指标,但不用于评估试验。
Algorithm。在本实验中,我们使用了随机搜索;某些算法可能需要额外的配置。
Budget configurations:这是我们配置实验预算的地方。在本实验中,我们将并行运行3个试验,总共进行12个试验。如果出现三个失败的试验,我们也将停止实验。这最后一部分也被称为错误预算——这是维持生产级系统正常运行时间的重要概念。
Parameters:在此我们定义需要调优的参数及其搜索空间。例如,学习率参数在训练代码中通过`--lr`暴露。它是一个双精度浮点数,搜索空间为连续的0.01至0.03。
Trial template:实验规范的最后一部分是每个试验配置的模板。在本示例中,唯一重要的部分是:

配置完成后,应用资源以启动实验:

2.3、调参分布式作业
在第7章中,我们看到了一个使用Kubeflow编排分布式训练的示例。如果我们想使用Katib来调优分布式训练任务的参数呢?好消息是,Katib原生支持与TensorFlow和PyTorch分布式训练的集成。一个使用TensorFlow的MNIST示例可以在Katib的GitHub页面上找到。这个示例使用了我们在第7章中看到的相同的MNIST分布式训练示例,并直接将其集成到Katib框架中。在示例10-3中,我们将启动一个实验来调优分布式TensorFlow任务的超参数(学习率和批量大小)。


总trial次数和并行trial次数与之前的trial相似。在这种情况下,它们指的是要运行的分布式训练任务的总数和并行数。
objective也类似——在这种情况下,我们希望最大化准确度测量。
指标收集器的规范略有不同。这是因为这是一个TensorFlow任务,我们可以直接使用TensorFlow输出的TFEvents。通过使用内置的TensorFlowEvent收集器类型,Katib可以自动解析TensorFlow事件并填充指标数据库。
参数配置完全相同——在这种情况下,我们正在调整模型的学习率和批量大小。

