

volcano plugin-1
Job和Task
关于所有的插件代码里有一个task和pod关系的问题:
看了一下官方的例子
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: test-job-webhook-disallow
spec:
schedulerName: volcano
minAvailable: 5 ## this job will be rejected because minAvailable is greater than total replicas in tasks
tasks:
- replicas: 2
name: task-1
template:
metadata:
name: web-1
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources:
requests:
cpu: "1"
restartPolicy: OnFailure
- replicas: 2
name: task-2
template:
metadata:
name: web-2
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources:
requests:
cpu: "1"
restartPolicy: OnFailure一个task确实是有replicas字段,也就是一个task里面有多个pod?
但是在所有的nodeorder函数里面都是一个task对一个node的评分,那task应该是一个pod呀?
在分析这个代码后,我查看了https://www.cnblogs.com/daniel-hutao/p/17935624.html:

大概的意思就是,这个yaml文件里面的task和调度器里的task不是一个概念,yaml里面的task对应rs这种级别资源,有多个pod,而调度器里面的task是一个pod。
控制器里面的task和job:
type TaskSpec struct {
Name string `json:"name,omitempty" protobuf:"bytes,1,opt,name=name"`
Replicas int32 `json:"replicas,omitempty" protobuf:"bytes,2,opt,name=replicas"`
MinAvailable *int32 `json:"minAvailable,omitempty" protobuf:"bytes,3,opt,name=minAvailable"`
Template v1.PodTemplateSpec `json:"template,omitempty" protobuf:"bytes,4,opt,name=template"`
Policies []LifecyclePolicy `json:"policies,omitempty" protobuf:"bytes,5,opt,name=policies"`
TopologyPolicy NumaPolicy `json:"topologyPolicy,omitempty" protobuf:"bytes,6,opt,name=topologyPolicy"`
MaxRetry int32 `json:"maxRetry,omitempty" protobuf:"bytes,7,opt,name=maxRetry"`
DependsOn *DependsOn `json:"dependsOn,omitempty" protobuf:"bytes,8,opt,name=dependsOn"`
}
// yaml定义的job
type JobSpec struct {
Name string
Namespace string
Queue string
Tasks []TaskSpec //job里面的tasks是一对taskspec
Policies []batchv1alpha1.LifecyclePolicy
Min int32
Pri string
Plugins map[string][]string
Volumes []batchv1alpha1.VolumeSpec
NodeName string
// ttl seconds after job finished
TTL *int32
MinSuccess *int32
// job max retry
MaxRetry int32
}调度器里面的task和job:
type TaskInfo struct {
UID TaskID
Job JobID
Name string
Namespace string
TaskRole string // value of "volcano.sh/task-spec"
Resreq *Resource
InitResreq *Resource
TransactionContext
LastTransaction *TransactionContext
Priority int32
VolumeReady bool
Preemptable bool
BestEffort bool
HasRestartableInitContainer bool
SchGated bool
RevocableZone string
NumaInfo *TopologyInfo
PodVolumes *volumescheduling.PodVolumes
Pod *v1.Pod // 可以看到对应一个pod
CustomBindErrHandler func() error `json:"-"`
CustomBindErrHandlerSucceeded bool
}
type JobInfo struct {
Namespace string
Name string
Job *batch.Job
Pods map[string]map[string]*v1.Pod
}这个是一个很关键的概念点了。调度器里的task是一个pod,而控制器里task是一个rs级别的资源,对应多个pod。
写yaml的时候,那个task是控制器里的taskspec,而调度器里的task是taskinfo。
在源码中找到taskspec和taskinfo的桥梁:
// job_controller_actions.go
for _, ts := range job.Spec.Tasks {
ts.Template.Name = ts.Name
tc := ts.Template.DeepCopy()
name := ts.Template.Name
pods, found := jobInfo.Pods[name]
if !found {
pods = map[string]*v1.Pod{}
}
var podToCreateEachTask []*v1.Pod
for i := 0; i < int(ts.Replicas); i++ {
podName := fmt.Sprintf(jobhelpers.PodNameFmt, job.Name, name, i)
if pod, found := pods[podName]; !found {
newPod := createJobPod(job, tc, ts.TopologyPolicy, i, jobForwarding)
if err := cc.pluginOnPodCreate(job, newPod); err != nil {
return err
}
podToCreateEachTask = append(podToCreateEachTask, newPod)
waitCreationGroup.Add(1)
} else {
delete(pods, podName)
if pod.DeletionTimestamp != nil {
klog.Infof("Pod <%s/%s> is terminating", pod.Namespace, pod.Name)
atomic.AddInt32(&terminating, 1)
continue
}
classifyAndAddUpPodBaseOnPhase(pod, &pending, &running, &succeeded, &failed, &unknown)
calcPodStatus(pod, taskStatusCount)
}
}
podToCreate[ts.Name] = podToCreateEachTask
for _, pod := range pods {
podToDelete = append(podToDelete, pod)
}
}会根据taskspec里面的replicas字段还有template构建出pod。
然后在job_info.go文件里面,再把一个pod包装成一个taskinfo进入调度器。
// NewTaskInfo creates new taskInfo object for a Pod
func NewTaskInfo(pod *v1.Pod) *TaskInfo {
initResReq := GetPodResourceRequest(pod)
resReq := initResReq
bestEffort := initResReq.IsEmpty()
preemptable := GetPodPreemptable(pod)
revocableZone := GetPodRevocableZone(pod)
topologyInfo := GetPodTopologyInfo(pod)
role := getTaskRole(pod)
hasRestartableInitContainer := hasRestartableInitContainer(pod)
// initialize pod scheduling gates info here since it will not change in a scheduling cycle
schGated := calSchedulingGated(pod)
jobID := getJobID(pod)
ti := &TaskInfo{
UID: TaskID(pod.UID),
Job: jobID,
Name: pod.Name,
Namespace: pod.Namespace,
TaskRole: role,
Priority: 1,
Pod: pod,
Resreq: resReq,
InitResreq: initResReq,
Preemptable: preemptable,
BestEffort: bestEffort,
HasRestartableInitContainer: hasRestartableInitContainer,
RevocableZone: revocableZone,
NumaInfo: topologyInfo,
SchGated: schGated,
TransactionContext: TransactionContext{
NodeName: pod.Spec.NodeName,
Status: getTaskStatus(pod),
},
}
if pod.Spec.Priority != nil {
ti.Priority = *pod.Spec.Priority
}
if taskPriority, ok := pod.Annotations[TaskPriorityAnnotation]; ok {
if priority, err := strconv.ParseInt(taskPriority, 10, 32); err == nil {
ti.Priority = int32(priority)
}
}
return ti
}综上,总结一下调度流程:
yaml文件定义job,在这个文件中会包括job里面tasks的replicas和template
控制器根据replicas和template生成replicas个数的pod
SchedulerCache执行NewTaskInfo将一个pod转换成一个taskinfo
taskinfo进入调度器进行调度
gang
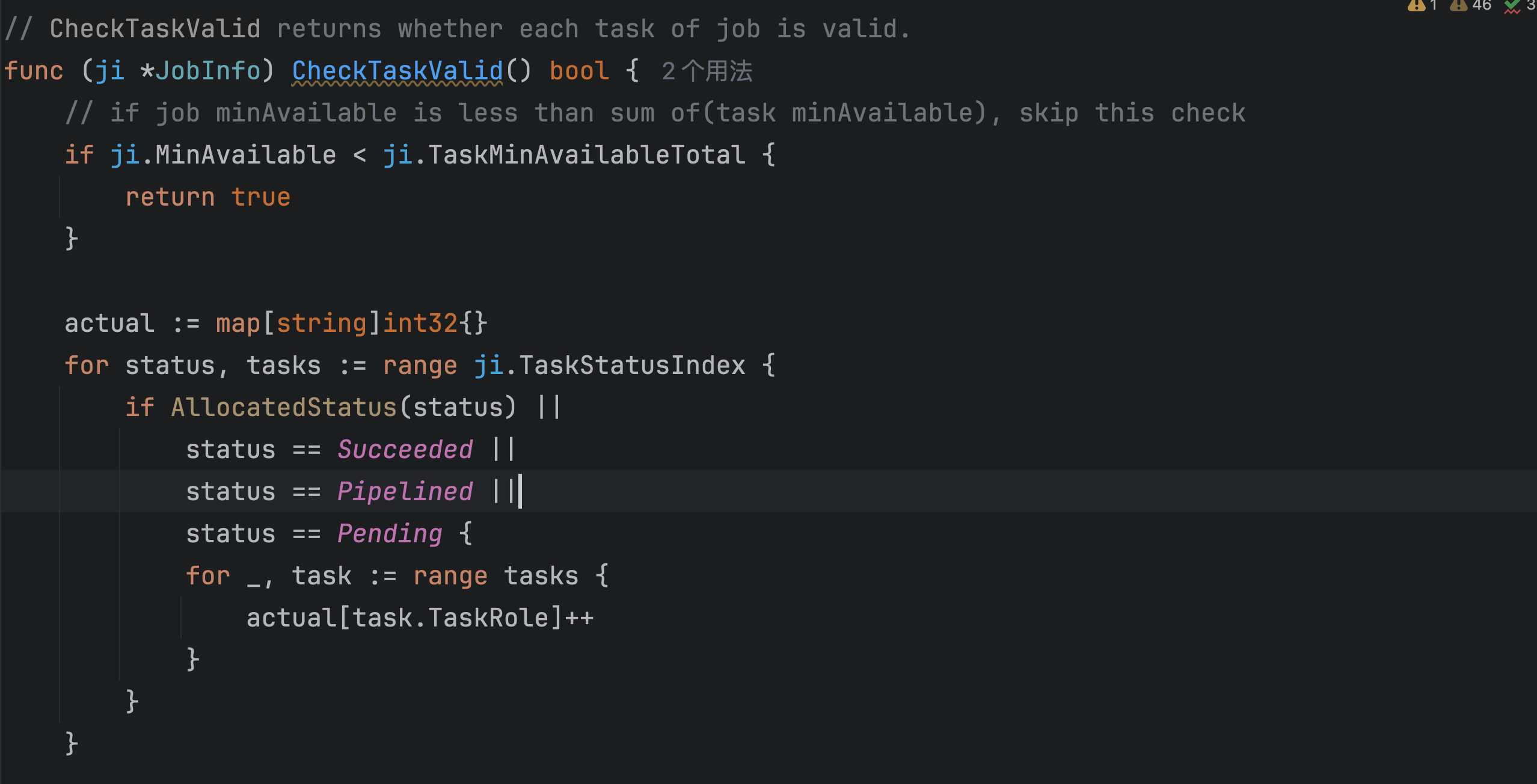
在 Volcano 调度器中,Gang 插件(组调度插件)用于确保Job的所有tasks要么全部调度成功,要么都不调度。以下是对该插件代码的详细分析:
func (gp *gangPlugin) OnSessionOpen(ssn *framework.Session) {
// 阻止不满足 MinAvailable(最小可用task)的Job进入调度队列
// 避免资源碎片(防止部分任务占用资源但整个作业无法运行)
validJobFn := func(obj interface{}) *api.ValidateResult {
job, ok := obj.(*api.JobInfo)
if !ok {
return &api.ValidateResult{
Pass: false,
Message: fmt.Sprintf("Failed to convert <%v> to *JobInfo", obj),
}
}
// 确保 job中每个task都满足最低有效 Pod 数量
if valid := job.CheckTaskValid(); !valid {
return &api.ValidateResult{
Pass: false,
Reason: v1beta1.NotEnoughPodsOfTaskReason,
Message: "Not enough valid pods of each task for gang-scheduling",
}
}
// 确保 整个Job 的有效task数达到最低要求
vtn := job.ValidTaskNum()
if vtn < job.MinAvailable {
return &api.ValidateResult{
Pass: false,
Reason: v1beta1.NotEnoughPodsReason,
Message: fmt.Sprintf("Not enough valid tasks for gang-scheduling, valid: %d, min: %d",
vtn, job.MinAvailable),
}
}
return nil
}
ssn.AddJobValidFn(gp.Name(), validJobFn)
// 防止抢占导致作业可用任务数低于 MinAvailable
// 保障 Gang 调度的原子性(要么全保留,要么全释放)
preemptableFn := func(preemptor *api.TaskInfo, preemptees []*api.TaskInfo) ([]*api.TaskInfo, int) {
var victims []*api.TaskInfo
jobOccupiedMap := map[api.JobID]int32{}
for _, preemptee := range preemptees {
job := ssn.Jobs[preemptee.Job]
if _, found := jobOccupiedMap[job.UID]; !found {
jobOccupiedMap[job.UID] = job.ReadyTaskNum()
}
if jobOccupiedMap[job.UID] > job.MinAvailable {
// 允许抢占仅当:抢占后该作业的可用任务仍 >= MinAvailable
jobOccupiedMap[job.UID]--
victims = append(victims, preemptee)
} else {
klog.V(4).Infof("Can not preempt task <%v/%v> because job %s ready num(%d) <= MinAvailable(%d) for gang-scheduling",
preemptee.Namespace, preemptee.Name, job.Name, jobOccupiedMap[job.UID], job.MinAvailable)
}
}
klog.V(4).Infof("Victims from Gang plugins, victims=%+v preemptor=%s", victims, preemptor)
return victims, util.Permit
}
// TODO(k82cn): Support preempt/reclaim batch job.
ssn.AddReclaimableFn(gp.Name(), preemptableFn)
ssn.AddPreemptableFn(gp.Name(), preemptableFn)
jobOrderFn := func(l, r interface{}) int {
lv := l.(*api.JobInfo)
rv := r.(*api.JobInfo)
lReady := lv.IsReady()
rReady := rv.IsReady()
klog.V(4).Infof("Gang JobOrderFn: <%v/%v> is ready: %t, <%v/%v> is ready: %t",
lv.Namespace, lv.Name, lReady, rv.Namespace, rv.Name, rReady)
if lReady && rReady {
return 0
}
if lReady {
return 1
}
if rReady {
return -1
}
return 0
}
ssn.AddJobOrderFn(gp.Name(), jobOrderFn)
ssn.AddJobReadyFn(gp.Name(), func(obj interface{}) bool {
ji := obj.(*api.JobInfo)
if ji.CheckTaskReady() && ji.IsReady() { // 任务数和 MinAvailable 均满足
return true
}
return false
})
// 允许进入预调度阶段
pipelinedFn := func(obj interface{}) int {
ji := obj.(*api.JobInfo)
if ji.CheckTaskPipelined() && ji.IsPipelined() {
return util.Permit
}
return util.Reject
}
ssn.AddJobPipelinedFn(gp.Name(), pipelinedFn)
// 监控价值:帮助识别长期无法调度的作业,可用于触发告警或弹性伸缩。
jobStarvingFn := func(obj interface{}) bool {
ji := obj.(*api.JobInfo)
// In the preemption scenario, the taskMinAvailable configuration is not concerned, only the jobMinAvailable is concerned
return ji.IsStarving()
}
ssn.AddJobStarvingFns(gp.Name(), jobStarvingFn)
}
在 Volcano 调度器的 Gang 插件中,确实存在一种 弹性调度机制:当作业级 minAvailable 小于 所有 Task 的 minAvailable 总和时,作业的全局优先级更高。此时即使某些 Task 的可用 Pod 未达到自身要求(即 task.minAvailable),只要作业整体的有效 Pod 总数 ≥ 作业级 minAvailable,作业仍然会被视为有效,允许调度。(Job的调度等级高,即使里面task不是每个都准备好了,但是Job满足了一样会调度)。
当作业的全局需求较低时,允许任务层面的弹性。例如:
task1 实际有 1 个 Pod(需求 2)
task2 实际有 2 个 Pod(需求 3)
总可用 Pod 数 = 1 + 2 = 3 ≥
ji.MinAvailable = 3
作业仍可调度,部分任务未达自身要求但满足全局需求。
此外在上面的代码里有一个joborderfn很有意思,
jobOrderFn := func(l, r interface{}) int {
lv := l.(*api.JobInfo)
rv := r.(*api.JobInfo)
lReady := lv.IsReady()
rReady := rv.IsReady()
klog.V(4).Infof("Gang JobOrderFn: <%v/%v> is ready: %t, <%v/%v> is ready: %t",
lv.Namespace, lv.Name, lReady, rv.Namespace, rv.Name, rReady)
if lReady && rReady {
return 0
}
if lReady {
return 1
}
if rReady {
return -1
}
return 0
}看到其他的排序函数,如果想优先处理左侧job,会返回-1,优先处理右job,会返回1,但是这个函数的返回值是相反的。
问了一下社区成员,他的回复是:如果Job是ready的,就意味着这个job已经有了满足minavailable的副本了,可以正常运行了,所以让他们优先级降低,优先去处理没有满足最低副本数的任务。这样做就可以让更多的job去运行,避免因为一个大job饿死其他小job。
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
spec:
minAvailable: 3 # 要求至少3个Pod运行
tasks:
- replicas: 5 # 总需5个Pod
template: ...就像类似于上面这个任务,在第三个pod选择了node后,已经满足了minavailable的要求了,这三个pod会一起调度下去,然后在处理第四个和第五个pod的时候,发现这个job已经是ready的状态了,所以这两个pod就会降低优先级,让其他job先调度。
binpack
模拟task分配到node的场景,如果分配到node后,节点资源使用率高,则得分高。
这个插件就是要把任务放在资源使用最高的节点上,减少资源碎片化。
这段代码是 BinPackingScore 函数,用于计算任务在节点上的装箱得分。其目的是通过最佳适配策略减少集群中稀缺资源的碎片化。以下是对该函数的详细分析:
func BinPackingScore(task *api.TaskInfo, node *api.NodeInfo, weight priorityWeight) float64 {
score := 0.0
weightSum := 0
requested := task.Resreq
allocatable := node.Allocatable
used := node.Used
for _, resource := range requested.ResourceNames() {
request := requested.Get(resource)
if request == 0 {
continue
}
allocate := allocatable.Get(resource)
nodeUsed := used.Get(resource)
resourceWeight, found := weight.BinPackingResources[resource]
if !found {
continue
}
resourceScore, err := ResourceBinPackingScore(request, allocate, nodeUsed, resourceWeight)
if err != nil {
klog.V(4).Infof("task %s/%s cannot binpack node %s: resource: %s is %s, need %f, used %f, allocatable %f",
task.Namespace, task.Name, node.Name, resource, err.Error(), request, nodeUsed, allocate)
return 0
}
klog.V(5).Infof("task %s/%s on node %s resource %s, need %f, used %f, allocatable %f, weight %d, score %f",
task.Namespace, task.Name, node.Name, resource, request, nodeUsed, allocate, resourceWeight, resourceScore)
score += resourceScore
weightSum += resourceWeight
}
// mapping the result from [0, weightSum] to [0, 10(MaxPriority)]
if weightSum > 0 {
score /= float64(weightSum)
}
score *= float64(k8sFramework.MaxNodeScore * int64(weight.BinPackingWeight))
return score
}func BinPackingScore(task api.TaskInfo, node api.NodeInfo, weight priorityWeight) float64
task: 需要计算得分的任务。
node: 任务要调度到的节点。
weight: 用于装箱算法的不同资源的权重。(CPU、内存、存储)1、初始化变量:
score: 累积总的装箱得分。
weightSum: 累积考虑的资源的权重总和。
requested: 任务请求的资源。
allocatable: 节点可分配的资源。
used: 节点已使用的资源。
2、遍历请求的资源:
对于任务请求的每个资源,获取请求量、节点可分配量和节点已使用量。
3、计算资源得分:
对于每个资源,从 weight 结构中获取相应的权重。
调用 ResourceBinPackingScore 函数,根据请求量、可分配量、已使用量和权重计算该资源的得分。
4、累积得分:
将资源得分加到总 score 中。
将资源权重加到 weightSum 中。
5、归一化和缩放得分:
将总得分归一化,除以 weightSum。
将归一化后的得分缩放到 [0, 10] 范围(最大节点得分),并乘以整体装箱权重。
6、返回最终得分:
返回最终的装箱得分。
// ResourceBinPackingScore calculate the binpack score for resource with provided info
func ResourceBinPackingScore(requested, capacity, used float64, weight int) (float64, error) {
if capacity == 0 || weight == 0 {
return 0, nil
}
usedFinally := requested + used
if usedFinally > capacity {
return 0, fmt.Errorf("not enough")
}
score := usedFinally * float64(weight) / capacity
return score, nil
}func ResourceBinPackingScore(requested, capacity, used float64, weight int) (float64, error)
函数计算给定资源的装箱得分。
参数:
requested: 请求的资源量。
capacity: 资源的总容量。
used: 已使用的资源量。
weight: 资源的权重。
返回值:
返回计算出的得分和可能的错误步骤:
1、如果 capacity 或 weight 为 0,返回得分 0。
2、计算 usedFinally,即请求的资源量加上已使用的资源量。
3、如果 usedFinally 超过 capacity,返回错误 "not enough"。
4、计算得分,公式为 usedFinally * float64(weight) / capacity。
func (bp *binpackPlugin) OnSessionOpen(ssn *framework.Session) {
klog.V(5).Infof("Enter binpack plugin ...")
defer func() {
klog.V(5).Infof("Leaving binpack plugin. %s ...", bp.weight.String())
}()
if klog.V(4).Enabled() {
notFoundResource := []string{}
for resource := range bp.weight.BinPackingResources {
found := false
for _, nodeInfo := range ssn.Nodes {
if nodeInfo.Allocatable.Get(resource) > 0 {
found = true
break
}
}
if !found {
notFoundResource = append(notFoundResource, string(resource))
}
}
klog.V(4).Infof("resources [%s] record in weight but not found on any node", strings.Join(notFoundResource, ", "))
}
nodeOrderFn := func(task *api.TaskInfo, node *api.NodeInfo) (float64, error) {
binPackingScore := BinPackingScore(task, node, bp.weight)
klog.V(4).Infof("Binpack score for Task %s/%s on node %s is: %v", task.Namespace, task.Name, node.Name, binPackingScore)
return binPackingScore, nil
}
if bp.weight.BinPackingWeight != 0 {
ssn.AddNodeOrderFn(bp.Name(), nodeOrderFn)
} else {
klog.Infof("binpack weight is zero, skip node order function")
}
}1、资源检查:
检查 BinPackingResources 中指定的资源是否在会话中的任何节点上可用。如果在任何节点上找不到某个资源,则记录一条日志消息。
2、节点排序函数:
定义一个 nodeOrderFn 函数,该函数使用 BinPackingScore 函数计算任务在节点上的装箱得分。
为每个任务和节点记录装箱得分。
添加节点排序函数:
如果 BinPackingWeight 不为零,则使用 ssn.AddNodeOrderFn 将 nodeOrderFn 添加到会话中。
capacity
这段代码是 Volcano 调度器中的一个容量管理插件,用于实现多队列的资源配额管理和层次化调度。以下是对代码的深入分析:
/*
Copyright 2024 The Volcano Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package capacity
import (
"fmt"
"math"
v1 "k8s.io/api/core/v1"
"k8s.io/klog/v2"
"volcano.sh/apis/pkg/apis/scheduling"
"volcano.sh/volcano/pkg/scheduler/api"
"volcano.sh/volcano/pkg/scheduler/api/helpers"
"volcano.sh/volcano/pkg/scheduler/framework"
"volcano.sh/volcano/pkg/scheduler/metrics"
"volcano.sh/volcano/pkg/scheduler/plugins/util"
)
const (
PluginName = "capacity"
rootQueueID = "root"
)
// capacityPlugin
// 主插件结构,维护全局资源状态和队列属性:
// rootQueue: 根队列标识
// totalResource: 集群总资源
// totalGuarantee: 所有队列保障资源总和
// queueOpts: 各队列的属性映射表
type capacityPlugin struct {
rootQueue string
totalResource *api.Resource
totalGuarantee *api.Resource
queueOpts map[api.QueueID]*queueAttr
// Arguments given for the plugin
pluginArguments framework.Arguments
}
// 队列的详细资源属性:
// deserved/allocated/request: 应得/已分配/请求资源
// capability/realCapability: 队列能力上限
// guarantee: 资源保障下限
// share: 资源使用率指标
// 层次化结构字段(ancestors/children)
// Guarantee
// 确保队列获得预设的最低资源(即使超卖)。通过 totalGuarantee 跟踪全局保障资源。
// Capability
// 硬性资源上限,通过 realCapability 动态计算(考虑父队列的限制)。
type queueAttr struct {
queueID api.QueueID
name string
share float64
ancestors []api.QueueID
children map[api.QueueID]*queueAttr
deserved *api.Resource
allocated *api.Resource
request *api.Resource
// elastic represents the sum of job's elastic resource, job's elastic = job.allocated - job.minAvailable
elastic *api.Resource
// inqueue represents the resource request of the inqueue job
inqueue *api.Resource
capability *api.Resource
// realCapability represents the resource limit of the queue, LessEqual capability
realCapability *api.Resource
guarantee *api.Resource
}
// New return capacityPlugin action
func New(arguments framework.Arguments) framework.Plugin {
return &capacityPlugin{
totalResource: api.EmptyResource(),
totalGuarantee: api.EmptyResource(),
queueOpts: map[api.QueueID]*queueAttr{},
pluginArguments: arguments,
}
}
func (cp *capacityPlugin) Name() string {
return PluginName
}
// HierarchyEnabled returns if hierarchy is enabled
func (cp *capacityPlugin) HierarchyEnabled(ssn *framework.Session) bool {
for _, tier := range ssn.Tiers {
for _, plugin := range tier.Plugins {
if plugin.Name != PluginName {
continue
}
return plugin.EnabledHierarchy != nil && *plugin.EnabledHierarchy
}
}
return false
}
func (cp *capacityPlugin) OnSessionOpen(ssn *framework.Session) {
// Prepare scheduling data for this session.
cp.totalResource.Add(ssn.TotalResource)
klog.V(4).Infof("The total resource is <%v>", cp.totalResource)
hierarchyEnabled := cp.HierarchyEnabled(ssn)
readyToSchedule := true
if hierarchyEnabled {
readyToSchedule = cp.buildHierarchicalQueueAttrs(ssn)
} else {
cp.buildQueueAttrs(ssn)
}
// 判断哪些任务可被抢占:当队列的已分配资源超过 deserved 且不违反保障资源时,允许回收。
ssn.AddReclaimableFn(cp.Name(), func(reclaimer *api.TaskInfo, reclaimees []*api.TaskInfo) ([]*api.TaskInfo, int) {
var victims []*api.TaskInfo
allocations := map[api.QueueID]*api.Resource{}
if !readyToSchedule {
klog.V(3).Infof("Capacity plugin failed to check queue's hierarchical structure!")
return victims, util.Reject
}
for _, reclaimee := range reclaimees {
job := ssn.Jobs[reclaimee.Job]
attr := cp.queueOpts[job.Queue]
if _, found := allocations[job.Queue]; !found {
allocations[job.Queue] = attr.allocated.Clone()
}
allocated := allocations[job.Queue]
if allocated.LessPartly(reclaimer.Resreq, api.Zero) {
klog.V(3).Infof("Failed to allocate resource for Task <%s/%s> in Queue <%s>, not enough resource.",
reclaimee.Namespace, reclaimee.Name, job.Queue)
continue
}
exceptReclaimee := allocated.Clone().Sub(reclaimee.Resreq)
// When scalar resource not specified in deserved such as "pods", we should skip it and consider it as infinity,
// so the following first condition will be true and the current queue will not be reclaimed.
if allocated.LessEqual(attr.deserved, api.Infinity) || !attr.guarantee.LessEqual(exceptReclaimee, api.Zero) {
continue
}
allocated.Sub(reclaimee.Resreq)
victims = append(victims, reclaimee)
}
klog.V(4).Infof("Victims from capacity plugin, victims=%+v reclaimer=%s", victims, reclaimer)
return victims, util.Permit
})
// 抢占决策:当队列的 deserved 资源未被完全使用时,允许触发抢占。
ssn.AddPreemptiveFn(cp.Name(), func(obj interface{}, candidate interface{}) bool {
if !readyToSchedule {
klog.V(3).Infof("Capacity plugin failed to check queue's hierarchical structure!")
return false
}
queue := obj.(*api.QueueInfo)
task := candidate.(*api.TaskInfo)
attr := cp.queueOpts[queue.UID]
futureUsed := attr.allocated.Clone().Add(task.Resreq)
overused := !futureUsed.LessEqualWithDimension(attr.deserved, task.Resreq)
metrics.UpdateQueueOverused(attr.name, overused)
if overused {
klog.V(3).Infof("Queue <%v> can not reclaim, deserved <%v>, allocated <%v>, share <%v>",
queue.Name, attr.deserved, attr.allocated, attr.share)
}
// PreemptiveFn is the opposite of OverusedFn in proportion plugin cause as long as there is a one-dimensional
// resource whose deserved is greater than allocated, current task can reclaim by preempt others.
return !overused
})
queueAllocatable := func(queue *api.QueueInfo, candidate *api.TaskInfo) bool {
attr := cp.queueOpts[queue.UID]
futureUsed := attr.allocated.Clone().Add(candidate.Resreq)
allocatable := futureUsed.LessEqualWithDimension(attr.realCapability, candidate.Resreq)
if !allocatable {
klog.V(3).Infof("Queue <%v>: realCapability <%v>, allocated <%v>; Candidate <%v>: resource request <%v>",
queue.Name, attr.realCapability, attr.allocated, candidate.Name, candidate.Resreq)
}
return allocatable
}
// 任务分配校验:检查从当前队列到根队列的各级资源上限。
ssn.AddAllocatableFn(cp.Name(), func(queue *api.QueueInfo, candidate *api.TaskInfo) bool {
if !readyToSchedule {
klog.V(3).Infof("Capacity plugin failed to check queue's hierarchical structure!")
return false
}
if hierarchyEnabled && !cp.isLeafQueue(queue.UID) {
klog.V(3).Infof("Queue <%s> is not a leaf queue, can not allocate task <%s>.", queue.Name, candidate.Name)
return false
}
list := append(cp.queueOpts[queue.UID].ancestors, queue.UID)
for i := len(list) - 1; i >= 0; i-- {
if !queueAllocatable(ssn.Queues[list[i]], candidate) {
if klog.V(5).Enabled() {
for i--; i >= 0; i-- {
queueAllocatable(ssn.Queues[list[i]], candidate)
}
}
return false
}
}
return true
})
// 作业入队校验:确保队列的 realCapability 满足作业最低资源需求。
ssn.AddJobEnqueueableFn(cp.Name(), func(obj interface{}) int {
if !readyToSchedule {
klog.V(3).Infof("Capacity plugin failed to check queue's hierarchical structure!")
return util.Reject
}
job := obj.(*api.JobInfo)
queueID := job.Queue
if hierarchyEnabled && !cp.isLeafQueue(queueID) {
return util.Reject
}
attr := cp.queueOpts[queueID]
queue := ssn.Queues[queueID]
// If no capability is set, always enqueue the job.
if attr.realCapability == nil {
klog.V(4).Infof("Capability of queue <%s> was not set, allow job <%s/%s> to Inqueue.",
queue.Name, job.Namespace, job.Name)
return util.Permit
}
if job.PodGroup.Spec.MinResources == nil {
klog.V(4).Infof("job %s MinResources is null.", job.Name)
return util.Permit
}
minReq := job.GetMinResources()
klog.V(5).Infof("job %s min resource <%s>, queue %s capability <%s> allocated <%s> inqueue <%s> elastic <%s>",
job.Name, minReq.String(), queue.Name, attr.realCapability.String(), attr.allocated.String(), attr.inqueue.String(), attr.elastic.String())
// The queue resource quota limit has not reached
r := minReq.Clone().Add(attr.allocated).Add(attr.inqueue).Sub(attr.elastic)
inqueue := r.LessEqualWithDimension(attr.realCapability, minReq)
klog.V(5).Infof("job %s inqueue %v", job.Name, inqueue)
if inqueue {
attr.inqueue.Add(job.DeductSchGatedResources(minReq))
return util.Permit
}
ssn.RecordPodGroupEvent(job.PodGroup, v1.EventTypeNormal, string(scheduling.PodGroupUnschedulableType), "queue resource quota insufficient")
return util.Reject
})
// Register event handlers.
// 动态更新队列的 allocated 资源,并级联更新祖先队列的资源状态。
ssn.AddEventHandler(&framework.EventHandler{
AllocateFunc: func(event *framework.Event) {
job := ssn.Jobs[event.Task.Job]
attr := cp.queueOpts[job.Queue]
attr.allocated.Add(event.Task.Resreq)
metrics.UpdateQueueAllocated(attr.name, attr.allocated.MilliCPU, attr.allocated.Memory)
cp.updateShare(attr)
if hierarchyEnabled {
for _, ancestorID := range attr.ancestors {
ancestorAttr := cp.queueOpts[ancestorID]
ancestorAttr.allocated.Add(event.Task.Resreq)
}
}
klog.V(4).Infof("Capacity AllocateFunc: task <%v/%v>, resreq <%v>, share <%v>",
event.Task.Namespace, event.Task.Name, event.Task.Resreq, attr.share)
},
DeallocateFunc: func(event *framework.Event) {
job := ssn.Jobs[event.Task.Job]
attr := cp.queueOpts[job.Queue]
attr.allocated.Sub(event.Task.Resreq)
metrics.UpdateQueueAllocated(attr.name, attr.allocated.MilliCPU, attr.allocated.Memory)
cp.updateShare(attr)
if hierarchyEnabled {
for _, ancestorID := range attr.ancestors {
ancestorAttr := cp.queueOpts[ancestorID]
ancestorAttr.allocated.Sub(event.Task.Resreq)
}
}
klog.V(4).Infof("Capacity EvictFunc: task <%v/%v>, resreq <%v>, share <%v>",
event.Task.Namespace, event.Task.Name, event.Task.Resreq, attr.share)
},
})
}
func (cp *capacityPlugin) OnSessionClose(ssn *framework.Session) {
cp.totalResource = nil
cp.totalGuarantee = nil
cp.queueOpts = nil
}
func (cp *capacityPlugin) buildQueueAttrs(ssn *framework.Session) {
for _, queue := range ssn.Queues {
if len(queue.Queue.Spec.Guarantee.Resource) == 0 {
continue
}
guarantee := api.NewResource(queue.Queue.Spec.Guarantee.Resource)
cp.totalGuarantee.Add(guarantee)
}
klog.V(4).Infof("The total guarantee resource is <%v>", cp.totalGuarantee)
// Build attributes for Queues.
for _, job := range ssn.Jobs {
klog.V(4).Infof("Considering Job <%s/%s>.", job.Namespace, job.Name)
if _, found := cp.queueOpts[job.Queue]; !found {
queue := ssn.Queues[job.Queue]
attr := &queueAttr{
queueID: queue.UID,
name: queue.Name,
deserved: api.NewResource(queue.Queue.Spec.Deserved),
allocated: api.EmptyResource(),
request: api.EmptyResource(),
elastic: api.EmptyResource(),
inqueue: api.EmptyResource(),
guarantee: api.EmptyResource(),
}
if len(queue.Queue.Spec.Capability) != 0 {
attr.capability = api.NewResource(queue.Queue.Spec.Capability)
if attr.capability.MilliCPU <= 0 {
attr.capability.MilliCPU = math.MaxFloat64
}
if attr.capability.Memory <= 0 {
attr.capability.Memory = math.MaxFloat64
}
}
if len(queue.Queue.Spec.Guarantee.Resource) != 0 {
attr.guarantee = api.NewResource(queue.Queue.Spec.Guarantee.Resource)
}
realCapability := api.ExceededPart(cp.totalResource, cp.totalGuarantee).Add(attr.guarantee)
if attr.capability == nil {
attr.realCapability = realCapability
} else {
realCapability.MinDimensionResource(attr.capability, api.Infinity)
attr.realCapability = realCapability
}
cp.queueOpts[job.Queue] = attr
klog.V(4).Infof("Added Queue <%s> attributes.", job.Queue)
}
attr := cp.queueOpts[job.Queue]
for status, tasks := range job.TaskStatusIndex {
if api.AllocatedStatus(status) {
for _, t := range tasks {
attr.allocated.Add(t.Resreq)
attr.request.Add(t.Resreq)
}
} else if status == api.Pending {
for _, t := range tasks {
attr.request.Add(t.Resreq)
}
}
}
if job.PodGroup.Status.Phase == scheduling.PodGroupInqueue {
// deduct the resources of scheduling gated tasks in a job when calculating inqueued resources
// so that it will not block other jobs from being inqueued.
attr.inqueue.Add(job.DeductSchGatedResources(job.GetMinResources()))
}
// calculate inqueue resource for running jobs
// the judgement 'job.PodGroup.Status.Running >= job.PodGroup.Spec.MinMember' will work on cases such as the following condition:
// Considering a Spark job is completed(driver pod is completed) while the podgroup keeps running, the allocated resource will be reserved again if without the judgement.
if job.PodGroup.Status.Phase == scheduling.PodGroupRunning &&
job.PodGroup.Spec.MinResources != nil &&
int32(util.CalculateAllocatedTaskNum(job)) >= job.PodGroup.Spec.MinMember {
inqueued := util.GetInqueueResource(job, job.Allocated)
attr.inqueue.Add(job.DeductSchGatedResources(inqueued))
}
attr.elastic.Add(job.GetElasticResources())
klog.V(5).Infof("Queue %s allocated <%s> request <%s> inqueue <%s> elastic <%s>",
attr.name, attr.allocated.String(), attr.request.String(), attr.inqueue.String(), attr.elastic.String())
}
for _, attr := range cp.queueOpts {
if attr.realCapability != nil {
attr.deserved.MinDimensionResource(attr.realCapability, api.Infinity)
}
// When scalar resource not specified in deserved such as "pods", we should skip it and consider deserved resource as infinity.
attr.deserved.MinDimensionResource(attr.request, api.Infinity)
attr.deserved = helpers.Max(attr.deserved, attr.guarantee)
cp.updateShare(attr)
klog.V(4).Infof("The attributes of queue <%s> in capacity: deserved <%v>, realCapability <%v>, allocate <%v>, request <%v>, elastic <%v>, share <%0.2f>",
attr.name, attr.deserved, attr.realCapability, attr.allocated, attr.request, attr.elastic, attr.share)
}
// Record metrics
for queueID, queueInfo := range ssn.Queues {
queue := ssn.Queues[queueID]
if attr, ok := cp.queueOpts[queueID]; ok {
metrics.UpdateQueueDeserved(attr.name, attr.deserved.MilliCPU, attr.deserved.Memory)
metrics.UpdateQueueAllocated(attr.name, attr.allocated.MilliCPU, attr.allocated.Memory)
metrics.UpdateQueueRequest(attr.name, attr.request.MilliCPU, attr.request.Memory)
continue
}
deservedCPU, deservedMem := 0.0, 0.0
if queue.Queue.Spec.Deserved != nil {
deservedCPU = float64(queue.Queue.Spec.Deserved.Cpu().MilliValue())
deservedMem = float64(queue.Queue.Spec.Deserved.Memory().Value())
}
metrics.UpdateQueueDeserved(queueInfo.Name, deservedCPU, deservedMem)
metrics.UpdateQueueAllocated(queueInfo.Name, 0, 0)
metrics.UpdateQueueRequest(queueInfo.Name, 0, 0)
}
ssn.AddQueueOrderFn(cp.Name(), func(l, r interface{}) int {
lv := l.(*api.QueueInfo)
rv := r.(*api.QueueInfo)
if lv.Queue.Spec.Priority != rv.Queue.Spec.Priority {
// return negative means high priority
return int(rv.Queue.Spec.Priority) - int(lv.Queue.Spec.Priority)
}
if cp.queueOpts[lv.UID].share == cp.queueOpts[rv.UID].share {
return 0
}
if cp.queueOpts[lv.UID].share < cp.queueOpts[rv.UID].share {
return -1
}
return 1
})
}
// 通过 buildHierarchicalQueueAttrs 构建父子队列关系,每个队列维护祖先列表 ancestors 和子节点映射 children。
func (cp *capacityPlugin) buildHierarchicalQueueAttrs(ssn *framework.Session) bool {
// Set the root queue
cp.rootQueue = rootQueueID
// Initialize queue attributes
for _, queue := range ssn.Queues {
_, found := cp.queueOpts[queue.UID]
if found {
continue
}
attr := cp.newQueueAttr(queue)
cp.queueOpts[queue.UID] = attr
err := cp.updateAncestors(queue, ssn)
if err != nil {
klog.Errorf("Failed to update Queue <%s> attributes, error: %v", queue.Name, err)
return false
}
}
for _, job := range ssn.Jobs {
klog.V(4).Infof("Considering Job <%s/%s>.", job.Namespace, job.Name)
attr := cp.queueOpts[job.Queue]
if len(attr.children) > 0 {
klog.Errorf("The Queue <%s> of Job <%s/%s> is not leaf queue", attr.name, job.Namespace, job.Name)
return false
}
oldAllocated := attr.allocated.Clone()
oldRequest := attr.request.Clone()
oldInqueue := attr.inqueue.Clone()
oldElastic := attr.elastic.Clone()
for status, tasks := range job.TaskStatusIndex {
if api.AllocatedStatus(status) {
for _, t := range tasks {
attr.allocated.Add(t.Resreq)
attr.request.Add(t.Resreq)
}
} else if status == api.Pending {
for _, t := range tasks {
attr.request.Add(t.Resreq)
}
}
}
if job.PodGroup.Status.Phase == scheduling.PodGroupInqueue {
attr.inqueue.Add(job.DeductSchGatedResources(job.GetMinResources()))
}
// calculate inqueue resource for running jobs
// the judgement 'job.PodGroup.Status.Running >= job.PodGroup.Spec.MinMember' will work on cases such as the following condition:
// Considering a Spark job is completed(driver pod is completed) while the podgroup keeps running, the allocated resource will be reserved again if without the judgement.
if job.PodGroup.Status.Phase == scheduling.PodGroupRunning &&
job.PodGroup.Spec.MinResources != nil &&
int32(util.CalculateAllocatedTaskNum(job)) >= job.PodGroup.Spec.MinMember {
inqueued := util.GetInqueueResource(job, job.Allocated)
attr.inqueue.Add(job.DeductSchGatedResources(inqueued))
}
attr.elastic.Add(job.GetElasticResources())
for _, ancestor := range attr.ancestors {
ancestorAttr := cp.queueOpts[ancestor]
ancestorAttr.allocated.Add(attr.allocated.Clone().Sub(oldAllocated))
ancestorAttr.request.Add(attr.request.Clone().Sub(oldRequest))
ancestorAttr.inqueue.Add(attr.inqueue.Clone().Sub(oldInqueue))
ancestorAttr.elastic.Add(attr.elastic.Clone().Sub(oldElastic))
}
klog.V(5).Infof("Queue %s allocated <%s> request <%s> inqueue <%s> elastic <%s>",
attr.name, attr.allocated.String(), attr.request.String(), attr.inqueue.String(), attr.elastic.String())
}
// init root queue realCapability/capability/deserved as cp.totalResource
rootQueueAttr := cp.queueOpts[api.QueueID(cp.rootQueue)]
rootQueueAttr.capability = cp.totalResource
rootQueueAttr.realCapability = cp.totalResource
rootQueueAttr.deserved = cp.totalResource
// Check the hierarchical structure of queues
err := cp.checkHierarchicalQueue(rootQueueAttr)
if err != nil {
klog.Errorf("Failed to check queue's hierarchical structure, error: %v", err)
return false
}
klog.V(4).Infof("Successfully checked queue's hierarchical structure.")
// update session attributes
ssn.TotalGuarantee = cp.totalGuarantee
// Update share
for _, attr := range cp.queueOpts {
cp.updateShare(attr)
klog.V(4).Infof("The attributes of queue <%s> in capacity: deserved <%v>, realCapability <%v>, allocate <%v>, request <%v>, elastic <%v>, share <%0.2f>",
attr.name, attr.deserved, attr.realCapability, attr.allocated, attr.request, attr.elastic, attr.share)
}
// Record metrics
for queueID := range ssn.Queues {
attr := cp.queueOpts[queueID]
metrics.UpdateQueueDeserved(attr.name, attr.deserved.MilliCPU, attr.deserved.Memory)
metrics.UpdateQueueAllocated(attr.name, attr.allocated.MilliCPU, attr.allocated.Memory)
metrics.UpdateQueueRequest(attr.name, attr.request.MilliCPU, attr.request.Memory)
}
ssn.AddQueueOrderFn(cp.Name(), func(l, r interface{}) int {
lv := l.(*api.QueueInfo)
rv := r.(*api.QueueInfo)
if lv.Queue.Spec.Priority != rv.Queue.Spec.Priority {
// return negative means high priority
return int(rv.Queue.Spec.Priority) - int(lv.Queue.Spec.Priority)
}
lvLeaf := cp.isLeafQueue(lv.UID)
rvLeaf := cp.isLeafQueue(rv.UID)
if lvLeaf && !rvLeaf {
return -1
} else if !lvLeaf && rvLeaf {
return 1
} else if !lvLeaf && !rvLeaf {
if cp.queueOpts[lv.UID].share == cp.queueOpts[rv.UID].share {
return 0
}
if cp.queueOpts[lv.UID].share < cp.queueOpts[rv.UID].share {
return -1
}
return 1
}
lvAttr := cp.queueOpts[lv.UID]
rvAttr := cp.queueOpts[rv.UID]
level := getQueueLevel(lvAttr, rvAttr)
lvParentID := lvAttr.queueID
rvParentID := rvAttr.queueID
if level+1 < len(lvAttr.ancestors) {
lvParentID = lvAttr.ancestors[level+1]
}
if level+1 < len(rvAttr.ancestors) {
rvParentID = rvAttr.ancestors[level+1]
}
if cp.queueOpts[lvParentID].share == cp.queueOpts[rvParentID].share {
return 0
}
if cp.queueOpts[lvParentID].share < cp.queueOpts[rvParentID].share {
return -1
}
return 1
})
ssn.AddVictimQueueOrderFn(cp.Name(), func(l, r, preemptor interface{}) int {
lv := l.(*api.QueueInfo)
rv := r.(*api.QueueInfo)
pv := preemptor.(*api.QueueInfo)
lLevel := getQueueLevel(cp.queueOpts[lv.UID], cp.queueOpts[pv.UID])
rLevel := getQueueLevel(cp.queueOpts[rv.UID], cp.queueOpts[pv.UID])
if lLevel == rLevel {
return 0
}
if lLevel > rLevel {
return -1
}
return 1
})
return true
}
func (cp *capacityPlugin) newQueueAttr(queue *api.QueueInfo) *queueAttr {
attr := &queueAttr{
queueID: queue.UID,
name: queue.Name,
ancestors: make([]api.QueueID, 0),
children: make(map[api.QueueID]*queueAttr),
deserved: api.NewResource(queue.Queue.Spec.Deserved),
allocated: api.EmptyResource(),
request: api.EmptyResource(),
elastic: api.EmptyResource(),
inqueue: api.EmptyResource(),
guarantee: api.EmptyResource(),
capability: api.EmptyResource(),
}
if len(queue.Queue.Spec.Capability) != 0 {
attr.capability = api.NewResource(queue.Queue.Spec.Capability)
}
if len(queue.Queue.Spec.Guarantee.Resource) != 0 {
attr.guarantee = api.NewResource(queue.Queue.Spec.Guarantee.Resource)
}
return attr
}
func (cp *capacityPlugin) updateAncestors(queue *api.QueueInfo, ssn *framework.Session) error {
if queue.Name == cp.rootQueue {
return nil
}
parent := cp.rootQueue
if queue.Queue.Spec.Parent != "" {
parent = queue.Queue.Spec.Parent
}
if _, exist := ssn.Queues[api.QueueID(parent)]; !exist {
return fmt.Errorf("the queue %s has invalid parent queue %s", queue.Name, parent)
}
parentInfo := ssn.Queues[api.QueueID(parent)]
if _, found := cp.queueOpts[parentInfo.UID]; !found {
parentAttr := cp.newQueueAttr(parentInfo)
cp.queueOpts[parentAttr.queueID] = parentAttr
err := cp.updateAncestors(parentInfo, ssn)
if err != nil {
return err
}
}
cp.queueOpts[parentInfo.UID].children[queue.UID] = cp.queueOpts[queue.UID]
cp.queueOpts[queue.UID].ancestors = append(cp.queueOpts[parentInfo.UID].ancestors, parentInfo.UID)
return nil
}
// 父队列的 capability 必须 ≥ 所有子队列的 capability 之和,通过 checkHierarchicalQueue 递归验证。
func (cp *capacityPlugin) checkHierarchicalQueue(attr *queueAttr) error {
totalGuarantee := api.EmptyResource()
totalDeserved := api.EmptyResource()
for _, childAttr := range attr.children {
totalDeserved.Add(childAttr.deserved)
totalGuarantee.Add(childAttr.guarantee)
// if the user does not set CPU or memory in capability, we set the value to be the same as parent(we do not consider the situation where the user sets CPU or memory<=0)
if childAttr.capability.MilliCPU <= 0 {
childAttr.capability.MilliCPU = attr.capability.MilliCPU
}
if childAttr.capability.Memory <= 0 {
childAttr.capability.Memory = attr.capability.Memory
}
// Check if the parent queue's capability is less than the child queue's capability
if attr.capability.LessPartly(childAttr.capability, api.Zero) {
return fmt.Errorf("queue <%s> capability is less than its child queue <%s>", attr.name, childAttr.name)
}
}
if attr.name == cp.rootQueue {
attr.guarantee = totalGuarantee
cp.totalGuarantee = totalGuarantee
}
for _, childAttr := range attr.children {
realCapability := attr.realCapability.Clone().Sub(totalGuarantee).Add(childAttr.guarantee)
if childAttr.capability == nil {
childAttr.realCapability = realCapability
} else {
realCapability.MinDimensionResource(childAttr.capability, api.Infinity)
childAttr.realCapability = realCapability
}
oldDeserved := childAttr.deserved.Clone()
childAttr.deserved.MinDimensionResource(childAttr.realCapability, api.Infinity)
childAttr.deserved.MinDimensionResource(childAttr.request, api.Zero)
childAttr.deserved = helpers.Max(childAttr.deserved, childAttr.guarantee)
totalDeserved.Sub(oldDeserved).Add(childAttr.deserved)
}
// Check if the parent queue's deserved resources are less than the total deserved resources of child queues
if attr.deserved.LessPartly(totalDeserved, api.Zero) {
return fmt.Errorf("deserved resources of queue <%s> are less than the sum of its child queues' deserved resources", attr.name)
}
// Check if the parent queue's guarantee resources are less than the total guarantee resources of child queues
if attr.guarantee.LessPartly(totalGuarantee, api.Zero) {
return fmt.Errorf("guarantee resources of queue <%s> are less than the sum of its child queues' guarantee resources", attr.name)
}
for _, childAttr := range attr.children {
err := cp.checkHierarchicalQueue(childAttr)
if err != nil {
return err
}
}
return nil
}
// updateShare 根据 allocated/deserved 的比例计算队列的资源占用率,用于调度优先级。
func (cp *capacityPlugin) updateShare(attr *queueAttr) {
res := float64(0)
for _, rn := range attr.deserved.ResourceNames() {
res = max(res, helpers.Share(attr.allocated.Get(rn), attr.deserved.Get(rn)))
}
attr.share = res
metrics.UpdateQueueShare(attr.name, attr.share)
}
func (cp *capacityPlugin) isLeafQueue(queueID api.QueueID) bool {
return len(cp.queueOpts[queueID].children) == 0
}
func getQueueLevel(l *queueAttr, r *queueAttr) int {
level := 0
for i := 0; i < min(len(l.ancestors), len(r.ancestors)); i++ {
if l.ancestors[i] == r.ancestors[i] {
level = i
} else {
return level
}
}
return level
}1、deserved(应得资源): 队列的理论资源配额
deserved = Min(realCapability, Max(guarantee, request))
当某个队列的 allocated > deserved 时,调度器会标记该队列处于过载状态(overused),其低优先级任务可能被回收
2、allocated(已分配资源): 当前实际占用的资源
// 任务调度时增加
attr.allocated.Add(event.Task.Resreq)
// 任务释放时减少
attr.allocated.Sub(event.Task.Resreq)对应已调度 Pod 的实际资源占用(包括 Running/Pending 状态)
3、request(请求资源): 所有未完成任务的累积需求
// 包含所有状态(AllocatedStatus + Pending)的任务
for _, tasks := range job.TaskStatusIndex {
attr.request.Add(t.Resreq)
}4、elastic(弹性资源): 允许回收的弹性空间
elastic = job.allocated - job.minAvailable
Job 实际分配超出其最小需求的资源部分
已调度 Job 是否保留在队列中?
✅ 仍然保留在队列中,直到作业生命周期结束(Complete/Failed)
原因:队列需要持续跟踪资源状态,用于:
资源回收(Reclaim)决策
弹性伸缩(Elastic Quota)计算
队列额度(Capability)监控
cdp
这个文件定义了一个名为 CooldownProtectionPlugin 的插件,用于在调度过程中提供冷却保护。该插件确保在冷却保护条件下,任务的 Pod 不会被抢占。以下是对该文件的详细分析:
// 检查 Pod 的标签和注解,获取冷却时间。如果没有设置冷却时间或格式无效,则返回 false。
func (sp *CooldownProtectionPlugin) podCooldownTime(pod *v1.Pod) (value time.Duration, enabled bool) {
// check labels and annotations
v, ok := pod.Labels[v1beta1.CooldownTime]
if !ok {
v, ok = pod.Annotations[v1beta1.CooldownTime]
if !ok {
return 0, false
}
}
vi, err := time.ParseDuration(v)
if err != nil {
klog.Warningf("invalid time duration %s=%s", v1beta1.CooldownTime, v)
return 0, false
}
return vi, true
}// 定义了 preemptableFn 函数,用于确定哪些 Pod 可以被抢占。具体步骤如下:
// 遍历所有可能被抢占的 Pod。
// 检查每个 Pod 的冷却时间。
// 如果 Pod 没有设置冷却时间或冷却时间已过,则将其添加到 victims 列表中。
func (sp *CooldownProtectionPlugin) OnSessionOpen(ssn *framework.Session) {
preemptableFn := func(preemptor *api.TaskInfo, preemptees []*api.TaskInfo) ([]*api.TaskInfo, int) {
var victims []*api.TaskInfo
for _, preemptee := range preemptees {
cooldownTime, enabled := sp.podCooldownTime(preemptee.Pod)
if !enabled {
victims = append(victims, preemptee)
continue
}
pod := preemptee.Pod
// find the time of pod really transform to running
// only running pod check stable time, others all put into victims
stableFiltered := false
// 遍历 Pod 的状态条件,找到类型为 PodScheduled 且状态为 ConditionTrue 的条件。
// 检查该条件的最后转换时间加上冷却时间是否在当前时间之后。
// 如果是,则设置 stableFiltered 为 true,表示该 Pod 处于冷却保护时间内。
if pod.Status.Phase == v1.PodRunning {
// ensure pod is running and have ready state
for _, c := range pod.Status.Conditions {
if c.Type == v1.PodScheduled && c.Status == v1.ConditionTrue {
if c.LastTransitionTime.Add(cooldownTime).After(time.Now()) {
stableFiltered = true
}
break
}
}
}
if !stableFiltered {
victims = append(victims, preemptee)
}
}
klog.V(4).Infof("Victims from cdp plugins are %+v", victims)
return victims, util.Permit
}
klog.V(4).Info("plugin cdp session open")
ssn.AddPreemptableFn(sp.Name(), preemptableFn)
}conformance
这个文件定义了一个名为 conformancePlugin 的插件,用于在调度过程中避免特定的 Pod 被驱逐。以下是对该文件的详细分析:
定义了 evictableFn 函数,用于确定哪些 Pod 可以被驱逐。具体步骤如下:
1、遍历所有可能被驱逐的 Pod。
2、检查每个 Pod 的优先级类名。
3、跳过关键 Pod(如 SystemClusterCritical、SystemNodeCritical 或属于 kube-system 命名空间的 Pod)。
4、将其他 Pod 添加到 victims 列表中。
5、返回 victims 列表和 util.Permit。
func (pp *conformancePlugin) OnSessionOpen(ssn *framework.Session) {
evictableFn := func(evictor *api.TaskInfo, evictees []*api.TaskInfo) ([]*api.TaskInfo, int) {
var victims []*api.TaskInfo
for _, evictee := range evictees {
className := evictee.Pod.Spec.PriorityClassName
// Skip critical pod.
if className == scheduling.SystemClusterCritical ||
className == scheduling.SystemNodeCritical ||
evictee.Namespace == v1.NamespaceSystem {
continue
}
victims = append(victims, evictee)
}
return victims, util.Permit
}
ssn.AddPreemptableFn(pp.Name(), evictableFn)
ssn.AddReclaimableFn(pp.Name(), evictableFn)
}drf
Job有主导资源,queue也有主导资源
每个Job的主导资源(Dominant Resource)是其在集群中占用比例最大的资源类型
集群总资源:CPU=32C, Mem=128GB
JobA使用:8C/16GB → CPU占比25%,内存12.5% → 主导资源是CPU
JobB使用:4C/32GB → CPU12.5%,内存25% → 主导资源是内存队列的 share 在 Volcano 调度器的 DRF 插件中表示 该队列在当前层级下主导资源的使用占比,并通过权重调整后的值反映其在调度中的优先级。
集群总资源:CPU=32C,内存=128GB
队列A已分配:8C、24GB → CPU占比 25%,内存占比 18.75%
→ 主导资源是 CPU,share=0.25
queue的排序也要看DRF份额,job排序也要看DRF份额。(这个插件会提供queueorder和joborder)。
此时teamA优先调度,因其折算DRF值低。
hierarchicalNode表示队列节点层次结构及其对应的权重和 DRF 属性:
type hierarchicalNode struct {
parent *hierarchicalNode
attr *drfAttr
// If the node is a leaf node,
// request represents the request of the job.
request *api.Resource
weight float64
saturated bool
hierarchy string
children map[string]*hierarchicalNode
}drfAttr表示 DRF 属性,包括份额、主导资源和已分配资源。
type drfAttr struct {
share float64
dominantResource string
allocated *api.Resource
}drfPlugin表示 DRF 插件,包括总资源、总分配资源、作业属性、命名空间选项、层次结构根节点和插件参数。
type drfPlugin struct {
totalResource *api.Resource
totalAllocated *api.Resource
// Key is Job ID
jobAttrs map[api.JobID]*drfAttr
// map[namespaceName]->attr
namespaceOpts map[string]*drfAttr
// hierarchical tree root
hierarchicalRoot *hierarchicalNode
// Arguments given for the plugin
pluginArguments framework.Arguments
}HierarchyEnabled检查是否启用了层次结构。(启动DRF插件不一定就启动了层次)。plugin.EnabledHierarchy != nil 确保指针不是空指针,空指针不可以解引用。
// HierarchyEnabled returns if hierarchy is enabled
func (drf *drfPlugin) HierarchyEnabled(ssn *framework.Session) bool {
for _, tier := range ssn.Tiers {
for _, plugin := range tier.Plugins {
if plugin.Name != PluginName {
continue
}
return plugin.EnabledHierarchy != nil && *plugin.EnabledHierarchy
}
}
return false
}compareQueues比较两个队列的优先级。
compareQueues 方法通过层级遍历,按照以下规则比较两个队列的优先级:
1. 非饱和(saturated=false)的队列优先。
2. 按 share/weight 比值排序,值越小,优先级越高。
3. 逐级深入队列的层次结构,直到找到优先级不同的节点。
4. 如果所有层级都相同,则认为优先级相等。
返回值:
float64 类型:
负值(<0):lqueue 优先级更高。
正值(>0):rqueue 优先级更高。
零(0):两者优先级相等。
A-B < 0 A优先
越小越优先
func (drf *drfPlugin) compareQueues(root *hierarchicalNode, lqueue *api.QueueInfo, rqueue *api.QueueInfo) float64 {
lnode := root
lpaths := strings.Split(lqueue.Hierarchy, "/")
rnode := root
rpaths := strings.Split(rqueue.Hierarchy, "/")
for i, depth := 0, min(len(lpaths), len(rpaths)); i < depth; i++ {
// Saturated nodes have minimum priority,
// so that demanding nodes will be popped first.
// 饱和(saturated)意味着该节点的资源已经用尽,此时需要让资源需求更大的队列先执行。
// • 规则:
// • 未饱和 (!lnode.saturated) 的队列比已饱和 (rnode.saturated) 的队列优先级更高,返回 -1。
// • 已饱和的队列优先级较低,返回 1。
if !lnode.saturated && rnode.saturated {
return -1
}
if lnode.saturated && !rnode.saturated {
return 1
}
// share/weight 代表队列的资源分配优先级:
// • share 表示已分配资源。
// • weight 代表该队列的权重(优先级)。
// • share/weight 越小,代表队列的资源需求越大,应当优先调度。
// • 如果 share/weight 相等,则进入下一层级比较:
if lnode.attr.share/lnode.weight == rnode.attr.share/rnode.weight {
if i < depth-1 {
lnode = lnode.children[lpaths[i+1]]
rnode = rnode.children[rpaths[i+1]]
}
} else {
return lnode.attr.share/lnode.weight - rnode.attr.share/rnode.weight
}
}
return 0
}1. 初始化 DRF 资源管理器,加载当前 session 的资源信息。
2. 遍历所有 Job,计算 Job 已使用的资源。
3. 计算 Job 的 DRF 份额,并记录 Job 资源状态。
4. 如果启用层级调度,计算层级队列的资源占比。
5. 注册抢占逻辑(决定哪些任务可以被抢占)。
6. 注册队列排序 & 任务回收(管理层级调度)。
7. 注册 Job 排序(确保 Job 按照 DRF 规则公平执行)。
8. 监听任务分配 & 释放事件(动态更新 DRF 份额)。
func (drf *drfPlugin) OnSessionOpen(ssn *framework.Session) {
// Prepare scheduling data for this session.
// 1、初始化总资源
// ssn.TotalResource 代表整个集群的可用资源。
// drf.totalResource 记录当前 DRF 调度器所管理的资源总量。
drf.totalResource.Add(ssn.TotalResource)
klog.V(4).Infof("Total Allocatable %s", drf.totalResource)
hierarchyEnabled := drf.HierarchyEnabled(ssn)
// 处理每个job
// • 遍历 session 内的所有 job,为它们创建调度属性 drfAttr。
// • 计算 job 当前已分配的资源。
for _, job := range ssn.Jobs {
attr := &drfAttr{
allocated: api.EmptyResource(),
}
// job.TaskStatusIndex 维护了该 job 下所有 task 的状态。
// 如果 task 是 已分配状态,就把它的 Resreq(资源需求)累加到 attr.allocated 中。
for status, tasks := range job.TaskStatusIndex {
if api.AllocatedStatus(status) {
for _, t := range tasks {
attr.allocated.Add(t.Resreq)
}
}
}
// Calculate the init share of Job
// 计算job资源占比
// • updateJobShare 计算该 job 的 DRF 份额(share)。
// • drf.jobAttrs[job.UID] = attr 记录 job 相关的资源信息。
drf.updateJobShare(job.Namespace, job.Name, attr)
drf.jobAttrs[job.UID] = attr
if hierarchyEnabled {
queue := ssn.Queues[job.Queue]
drf.totalAllocated.Add(attr.allocated)
drf.UpdateHierarchicalShare(drf.hierarchicalRoot, drf.totalAllocated, job, attr, queue.Hierarchy, queue.Weights)
}
}
// • preemptableFn 负责判断某个任务是否可以抢占其他任务。
// • 核心逻辑:
// 1. 计算 preemptor(抢占者)的新 DRF share。
// 2. 遍历 preemptees(被抢占者),计算它们去掉 task 后的 DRF share。
// 3. 如果 preemptor 的 share 比 preemptee 低,或者 share 差距很小,则 preemptee 被抢占。
preemptableFn := func(preemptor *api.TaskInfo, preemptees []*api.TaskInfo) ([]*api.TaskInfo, int) {
var victims []*api.TaskInfo
addVictim := func(candidate *api.TaskInfo) {
victims = append(victims, candidate)
}
latt := drf.jobAttrs[preemptor.Job]
lalloc := latt.allocated.Clone().Add(preemptor.Resreq)
_, ls := drf.calculateShare(lalloc, drf.totalResource)
allocations := map[api.JobID]*api.Resource{}
for _, preemptee := range preemptees {
if _, found := allocations[preemptee.Job]; !found {
ratt := drf.jobAttrs[preemptee.Job]
allocations[preemptee.Job] = ratt.allocated.Clone()
}
ralloc := allocations[preemptee.Job].Sub(preemptee.Resreq)
_, rs := drf.calculateShare(ralloc, drf.totalResource)
if ls < rs || math.Abs(ls-rs) <= shareDelta {
addVictim(preemptee)
}
}
klog.V(4).Infof("Victims from DRF plugins are %+v", victims)
return victims, util.Permit
}
ssn.AddPreemptableFn(drf.Name(), preemptableFn)
// 如果启用了层次
// queueOrderFn 负责比较 两个队列的优先级,使用 compareQueues 方法。
// • reclaimFn 负责从低优先级的队列中回收资源:
// • 模拟资源回收过程,调整 HDRF(Hierarchical DRF)份额。
// • 如果 reclaimer(资源回收者)的 HDRF 低于 reclaimee(被回收者),则 reclaimee 被回收。
if hierarchyEnabled {
queueOrderFn := func(l interface{}, r interface{}) int {
lv := l.(*api.QueueInfo)
rv := r.(*api.QueueInfo)
ret := drf.compareQueues(drf.hierarchicalRoot, lv, rv)
if ret < 0 {
return -1
}
if ret > 0 {
return 1
}
return 0
}
ssn.AddQueueOrderFn(drf.Name(), queueOrderFn)
reclaimFn := func(reclaimer *api.TaskInfo, reclaimees []*api.TaskInfo) ([]*api.TaskInfo, int) {
var victims []*api.TaskInfo
// clone hdrf tree
totalAllocated := drf.totalAllocated.Clone()
root := drf.hierarchicalRoot.Clone(nil)
// update reclaimer hdrf
ljob := ssn.Jobs[reclaimer.Job]
lqueue := ssn.Queues[ljob.Queue]
ljob = ljob.Clone()
attr := drf.jobAttrs[ljob.UID]
lattr := &drfAttr{
allocated: attr.allocated.Clone(),
}
lattr.allocated.Add(reclaimer.Resreq)
totalAllocated.Add(reclaimer.Resreq)
drf.updateShare(lattr)
drf.UpdateHierarchicalShare(root, totalAllocated, ljob, lattr, lqueue.Hierarchy, lqueue.Weights)
for _, preemptee := range reclaimees {
rjob := ssn.Jobs[preemptee.Job]
rqueue := ssn.Queues[rjob.Queue]
// update hdrf of reclaimee job
totalAllocated.Sub(preemptee.Resreq)
rjob = rjob.Clone()
attr := drf.jobAttrs[rjob.UID]
rattr := &drfAttr{
allocated: attr.allocated.Clone(),
}
rattr.allocated.Sub(preemptee.Resreq)
drf.updateShare(rattr)
drf.UpdateHierarchicalShare(root, totalAllocated, rjob, rattr, rqueue.Hierarchy, rqueue.Weights)
// compare hdrf of queues
ret := drf.compareQueues(root, lqueue, rqueue)
// resume hdrf of reclaimee job
totalAllocated.Add(preemptee.Resreq)
rattr.allocated.Add(preemptee.Resreq)
drf.updateShare(rattr)
drf.UpdateHierarchicalShare(root, totalAllocated, rjob, rattr, rqueue.Hierarchy, rqueue.Weights)
if ret < 0 {
victims = append(victims, preemptee)
}
if ret > shareDelta {
continue
}
}
klog.V(4).Infof("Victims from HDRF plugins are %+v", victims)
return victims, util.Permit
}
ssn.AddReclaimableFn(drf.Name(), reclaimFn)
}
// • jobOrderFn 负责在 Job 调度时,按照 DRF 份额排序:
// • DRF share 小的 Job 优先执行(更公平)。
jobOrderFn := func(l interface{}, r interface{}) int {
lv := l.(*api.JobInfo)
rv := r.(*api.JobInfo)
klog.V(4).Infof("DRF JobOrderFn: <%v/%v> share state: %v, <%v/%v> share state: %v",
lv.Namespace, lv.Name, drf.jobAttrs[lv.UID].share, rv.Namespace, rv.Name, drf.jobAttrs[rv.UID].share)
if drf.jobAttrs[lv.UID].share == drf.jobAttrs[rv.UID].share {
return 0
}
if drf.jobAttrs[lv.UID].share < drf.jobAttrs[rv.UID].share {
return -1
}
return 1
}
ssn.AddJobOrderFn(drf.Name(), jobOrderFn)
// Register event handlers.
// • AllocateFunc:当 task 被分配资源时:
// • 记录 task 的 Resreq,更新 job 和 队列 的 DRF share。
// • DeallocateFunc:当 task 释放资源时:
// • 减去 task 的 Resreq,更新 job 和 队列 的 DRF share。
ssn.AddEventHandler(&framework.EventHandler{
AllocateFunc: func(event *framework.Event) {
attr := drf.jobAttrs[event.Task.Job]
attr.allocated.Add(event.Task.Resreq)
job := ssn.Jobs[event.Task.Job]
drf.updateJobShare(job.Namespace, job.Name, attr)
nsShare := -1.0
if hierarchyEnabled {
queue := ssn.Queues[job.Queue]
drf.totalAllocated.Add(event.Task.Resreq)
drf.UpdateHierarchicalShare(drf.hierarchicalRoot, drf.totalAllocated, job, attr, queue.Hierarchy, queue.Weights)
}
klog.V(4).Infof("DRF AllocateFunc: task <%v/%v>, resreq <%v>, share <%v>, namespace share <%v>",
event.Task.Namespace, event.Task.Name, event.Task.Resreq, attr.share, nsShare)
},
DeallocateFunc: func(event *framework.Event) {
attr := drf.jobAttrs[event.Task.Job]
attr.allocated.Sub(event.Task.Resreq)
job := ssn.Jobs[event.Task.Job]
drf.updateJobShare(job.Namespace, job.Name, attr)
nsShare := -1.0
if hierarchyEnabled {
queue := ssn.Queues[job.Queue]
drf.totalAllocated.Sub(event.Task.Resreq)
drf.UpdateHierarchicalShare(drf.hierarchicalRoot, drf.totalAllocated, job, attr, queue.Hierarchy, queue.Weights)
}
klog.V(4).Infof("DRF EvictFunc: task <%v/%v>, resreq <%v>, share <%v>, namespace share <%v>",
event.Task.Namespace, event.Task.Name, event.Task.Resreq, attr.share, nsShare)
},
})
}ssn.AddEventHandler 是用于注册调度事件监听器的核心方法。它允许插件在特定资源调度事件发生时执行自定义逻辑,是实现动态资源跟踪的核心机制。以下是详细解析:
实时状态同步:当任务被调度(分配资源)或释放(资源回收)时,自动更新相关队列/作业的资源使用数据
动态决策支持:触发重新计算 DRF 的 share 值等关键指标,为后续调度决策提供最新依据
级联更新:在层次化队列结构中,将资源变更向上传播到父队列
extender
extender 插件为 Volcano 提供一个外部扩展机制,允许将部分调度决策(如过滤、优先级、抢占等)委托给独立的外部服务。其核心功能如下:
type extenderConfig struct {
urlPrefix string
httpTimeout time.Duration
onSessionOpenVerb string
onSessionCloseVerb string
predicateVerb string
prioritizeVerb string
preemptableVerb string
reclaimableVerb string
queueOverusedVerb string
jobEnqueueableVerb string
jobReadyVerb string
ignorable bool
}Volcano Scheduler External Extender Service
+------------------+ +---------------------------+
| | HTTP | |
| extender plugin | <==============> | /predicate |
| | POST | /prioritize |
+------------------+ | /preemptable |
+---------------------------+请求类型:所有请求均为 HTTP POST,Body 为 JSON 格式
响应要求:
状态码
200 OKBody 包含 JSON 格式的响应数据(如
PredicateResponse)
func (ep *extenderPlugin) OnSessionOpen(ssn *framework.Session) {
// 1、通知外部服务,调度开始
if ep.config.onSessionOpenVerb != "" {
err := ep.send(ep.config.onSessionOpenVerb, &OnSessionOpenRequest{
Jobs: ssn.Jobs,
Nodes: ssn.Nodes,
Queues: ssn.Queues,
NamespaceInfo: ssn.NamespaceInfo,
RevocableNodes: ssn.RevocableNodes,
}, nil)
if err != nil {
klog.Warningf("OnSessionClose failed with error %v", err)
}
if err != nil && !ep.config.ignorable {
return
}
}
// 2、注册各类扩展回调函数,这些回调函数都是通过HTTP POST向指定的扩展调度器的地址去发请求,然后拿回结果。
// 自定义的调度器就是一个HTTP服务端,收到请求后,进入自己的处理逻辑,然后返回值就可以了。
if ep.config.predicateVerb != "" {
ssn.AddPredicateFn(ep.Name(), func(task *api.TaskInfo, node *api.NodeInfo) error {
resp := &PredicateResponse{}
err := ep.send(ep.config.predicateVerb, &PredicateRequest{Task: task, Node: node}, resp)
if err != nil {
klog.Warningf("Predicate failed with error %v", err)
if ep.config.ignorable {
return nil
}
return api.NewFitError(task, node, err.Error())
}
if len(resp.ErrorMessage) == 0 {
return nil
}
// keep compatibility with old behavior: error messages length is not zero,
// but didn't return a code, and code will be 0 for default. Change code to Error for corresponding
if resp.Code == api.Success {
resp.Code = api.Error
}
return api.NewFitErrWithStatus(task, node, &api.Status{Code: resp.Code, Reason: resp.ErrorMessage, Plugin: PluginName})
})
}
if ep.config.prioritizeVerb != "" {
ssn.AddBatchNodeOrderFn(ep.Name(), func(task *api.TaskInfo, nodes []*api.NodeInfo) (map[string]float64, error) {
resp := &PrioritizeResponse{}
err := ep.send(ep.config.prioritizeVerb, &PrioritizeRequest{Task: task, Nodes: nodes}, resp)
if err != nil {
klog.Warningf("Prioritize failed with error %v", err)
if ep.config.ignorable {
return nil, nil
}
return nil, err
}
if resp.ErrorMessage == "" && resp.NodeScore != nil {
return resp.NodeScore, nil
}
return nil, errors.New(resp.ErrorMessage)
})
}
if ep.config.preemptableVerb != "" {
ssn.AddPreemptableFn(ep.Name(), func(evictor *api.TaskInfo, evictees []*api.TaskInfo) ([]*api.TaskInfo, int) {
resp := &PreemptableResponse{}
err := ep.send(ep.config.preemptableVerb, &PreemptableRequest{Evictor: evictor, Evictees: evictees}, resp)
if err != nil {
klog.Warningf("Preemptable failed with error %v", err)
if ep.config.ignorable {
return nil, util.Permit
}
return nil, util.Reject
}
return resp.Victims, resp.Status
})
}
if ep.config.reclaimableVerb != "" {
ssn.AddReclaimableFn(ep.Name(), func(evictor *api.TaskInfo, evictees []*api.TaskInfo) ([]*api.TaskInfo, int) {
resp := &ReclaimableResponse{}
err := ep.send(ep.config.reclaimableVerb, &ReclaimableRequest{Evictor: evictor, Evictees: evictees}, resp)
if err != nil {
klog.Warningf("Reclaimable failed with error %v", err)
if ep.config.ignorable {
return nil, util.Permit
}
return nil, util.Reject
}
return resp.Victims, resp.Status
})
}
if ep.config.jobEnqueueableVerb != "" {
ssn.AddJobEnqueueableFn(ep.Name(), func(obj interface{}) int {
job := obj.(*api.JobInfo)
resp := &JobEnqueueableResponse{}
err := ep.send(ep.config.jobEnqueueableVerb, &JobEnqueueableRequest{Job: job}, resp)
if err != nil {
klog.Warningf("JobEnqueueable failed with error %v", err)
if ep.config.ignorable {
return util.Permit
}
return util.Reject
}
return resp.Status
})
}
if ep.config.queueOverusedVerb != "" {
ssn.AddOverusedFn(ep.Name(), func(obj interface{}) bool {
queue := obj.(*api.QueueInfo)
resp := &QueueOverusedResponse{}
err := ep.send(ep.config.queueOverusedVerb, &QueueOverusedRequest{Queue: queue}, resp)
if err != nil {
klog.Warningf("QueueOverused failed with error %v", err)
return !ep.config.ignorable
}
return resp.Overused
})
}
if ep.config.jobReadyVerb != "" {
ssn.AddJobReadyFn(ep.Name(), func(obj interface{}) bool {
job := obj.(*api.JobInfo)
resp := &JobReadyResponse{}
err := ep.send(ep.config.jobReadyVerb, &JobReadyRequest{Job: job}, resp)
if err != nil {
klog.Warningf("JobReady failed with error %v", err)
return !ep.config.ignorable
}
return resp.Status
})
}
}
func (ep *extenderPlugin) send(action string, args interface{}, result interface{}) error {
out, err := json.Marshal(args)
if err != nil {
return err
}
// URL 拼接:baseURL + verb(如 http://extender:8080/predicate)
// 超时控制:通过 ep.client.Timeout 限制 HTTP 请求最大耗时
url := strings.TrimRight(ep.config.urlPrefix, "/") + "/" + action
req, err := http.NewRequest("POST", url, bytes.NewReader(out))
if err != nil {
return err
}
req.Header.Set("Content-Type", "application/json")
// 强制要求:扩展服务必须返回 HTTP 200 状态码
// 反序列化:根据回调类型解析 JSON 到对应的 XXXResponse 结构体
resp, err := ep.client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return fmt.Errorf("failed %v with extender at URL %v, code %v", action, url, resp.StatusCode)
}
if result != nil {
return json.NewDecoder(resp.Body).Decode(result)
}
return nil
}通过对上面的代码分析,可以明白extender这个插件的作用:
如果启用了这个插件,就可以让volcano调度器与外部自定义调度器交互了,通过提前告诉volcano调度器,自定义调度器实现了哪些扩展点,在调度逻辑到对应位置后,volcano调度器就会向自定义调度器的对应url发送http post。自定义调度器拿到http.request之后就可以进入自己实现的逻辑了,执行完成后,再以HTTP形式返回。
nodegroup
该插件用于实现 队列与节点组(NodeGroup)的亲和性/反亲和性调度,核心功能包括:
节点过滤(Predicate):根据队列配置的亲和性/反亲和性规则过滤不满足条件的节点
节点排序(Node Ordering):根据亲和性规则为节点打分,优先选择符合要求的节点
type queueGroupAffinity struct {
queueGroupAntiAffinityRequired map[string]sets.Set[string] // 队列级硬反亲和性(禁止调度的节点组)
queueGroupAntiAffinityPreferred map[string]sets.Set[string] // 队列级软反亲和性(尽量避免的节点组)
queueGroupAffinityRequired map[string]sets.Set[string] // 队列级硬亲和性(必须调度的节点组)
queueGroupAffinityPreferred map[string]sets.Set[string] // 队列级软亲和性(优先选择的节点组)
}Key:队列名(如 default-queue)
Value:与该队列存在亲和性/反亲和性关系的节点组集合
func calculateArguments(ssn *framework.Session, args framework.Arguments) queueGroupAffinity {
queueGroupAffinity := NewQueueGroupAffinity()
for _, queue := range ssn.Queues {
// 从队列的 Spec.Affinity 中加载配置
if affinity := queue.Queue.Spec.Affinity; affinity != nil {
// 处理亲和性
if nodeGroupAffinity := affinity.NodeGroupAffinity; nodeGroupAffinity != nil {
// 硬亲和性 Required...
// 软亲和性 Preferred...
}
// 处理反亲和性
if nodeGroupAntiAffinity := affinity.NodeGroupAntiAffinity; nodeGroupAntiAffinity != nil {
// 硬反亲和性 Required...
// 软反亲和性 Preferred...
}
}
}
return queueGroupAffinity
}NodeGroupAffinity:定义队列需要亲和调度的节点组
NodeGroupAntiAffinity:定义队列需要反亲和调度的节点组
func (q queueGroupAffinity) predicate(queue, group string) error {
if len(queue) == 0 {
return nil
}
flag := false
if q.queueGroupAffinityRequired != nil {
if groups, ok := q.queueGroupAffinityRequired[queue]; ok {
if groups.Has(group) {
flag = true
}
}
}
if q.queueGroupAffinityPreferred != nil {
if groups, ok := q.queueGroupAffinityPreferred[queue]; ok {
if groups.Has(group) {
flag = true
}
}
}
// AntiAffinity: hard constraints should be checked first
// to make sure soft constraints satisfy
// and antiAffinity's priority is higher than affinity
if q.queueGroupAntiAffinityRequired != nil {
if groups, ok := q.queueGroupAntiAffinityRequired[queue]; ok {
if groups.Has(group) {
flag = false
}
}
}
if q.queueGroupAntiAffinityPreferred != nil {
if groups, ok := q.queueGroupAntiAffinityPreferred[queue]; ok {
if groups.Has(group) {
flag = true
}
}
}
if !flag {
return errors.New("not satisfy")
}
return nil
}节点过滤:
1、若队列对节点组有 硬反亲和性 → 禁止调度
2、若队列对节点组有 硬亲和性 → 必须调度到指定组
3、软规则不影响过滤,仅影响排序
func (np *nodeGroupPlugin) OnSessionOpen(ssn *framework.Session) {
queueGroupAffinity := calculateArguments(ssn, np.pluginArguments)
klog.V(4).Infof("queueGroupAffinity queueGroupAntiAffinityRequired <%v> queueGroupAntiAffinityPreferred <%v> queueGroupAffinityRequired <%v> queueGroupAffinityPreferred <%v> groupLabelName <%v>",
queueGroupAffinity.queueGroupAntiAffinityRequired, queueGroupAffinity.queueGroupAntiAffinityPreferred,
queueGroupAffinity.queueGroupAffinityRequired, queueGroupAffinity.queueGroupAffinityPreferred, NodeGroupNameKey)
nodeOrderFn := func(task *api.TaskInfo, node *api.NodeInfo) (float64, error) {
group := node.Node.Labels[NodeGroupNameKey]
queue := GetPodQueue(task)
score := queueGroupAffinity.score(queue, group)
klog.V(4).Infof("task <%s>/<%s> queue %s on node %s of nodegroup %s, score %v", task.Namespace, task.Name, queue, node.Name, group, score)
return score, nil
}
ssn.AddNodeOrderFn(np.Name(), nodeOrderFn)
predicateFn := func(task *api.TaskInfo, node *api.NodeInfo) error {
predicateStatus := make([]*api.Status, 0)
group := node.Node.Labels[NodeGroupNameKey]
queue := GetPodQueue(task)
if err := queueGroupAffinity.predicate(queue, group); err != nil {
nodeStatus := &api.Status{
Code: api.UnschedulableAndUnresolvable,
Reason: "node not satisfy",
}
predicateStatus = append(predicateStatus, nodeStatus)
return api.NewFitErrWithStatus(task, node, predicateStatus...)
}
klog.V(4).Infof("task <%s>/<%s> queue %s on node %s of nodegroup %v", task.Namespace, task.Name, queue, node.Name, group)
return nil
}
ssn.AddPredicateFn(np.Name(), predicateFn)
}看当前这个task属于的队列有没有配置亲和性和反亲和性,然后根据此评分:
因为亲和性是在queue级别定义的,所以task对node的评分,需要找到task属于的queue,找到queue对node的评分,再作为task对node的评分:
func (q queueGroupAffinity) score(queue string, group string) float64 {
nodeScore := 0.0
if len(queue) == 0 {
return nodeScore
}
// Affinity: hard constraints should be checked first
// to make sure soft constraints can cover score.
// And same to predict, antiAffinity's priority is higher than affinity
if q.queueGroupAffinityRequired != nil {
if groups, ok := q.queueGroupAffinityRequired[queue]; ok {
if groups.Has(group) {
// BaseScore = 100
nodeScore += BaseScore
}
}
}
if q.queueGroupAffinityPreferred != nil {
if groups, ok := q.queueGroupAffinityPreferred[queue]; ok {
if groups.Has(group) {
nodeScore += 0.5 * BaseScore
}
}
}
if q.queueGroupAntiAffinityPreferred != nil {
if groups, ok := q.queueGroupAntiAffinityPreferred[queue]; ok {
if groups.Has(group) {
nodeScore = -1
}
}
}
return nodeScore
}打分规则:

