

一、Docker 基础知识
本章作为书籍《自己动手写Docker》的读书笔记
1、Namespace
我们经常听到,Docker 是一个使用了 Linux Namespace 和 Cgroups 的虚拟化工具 。但是,什么是 Linux Namespace?
当前 Linux 一共实现了 6 种不同类型的 Namespace:
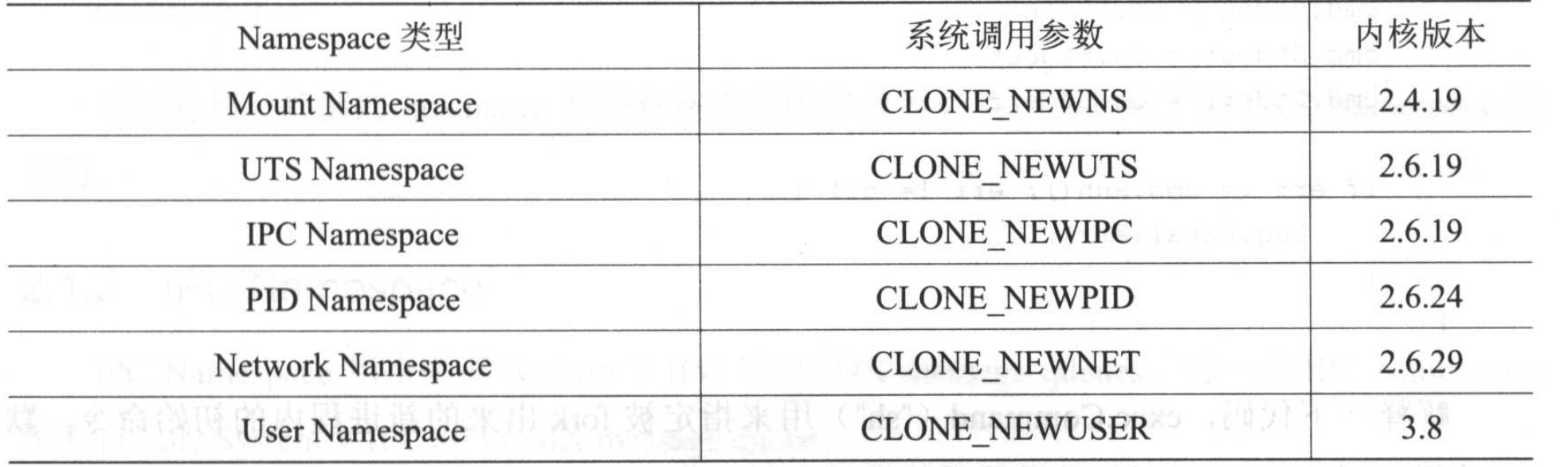
Namespace 的 API 主要使用如下 3 个系统调用:
clone()创建新进程。根据系统调用参数来判断哪些类型的 Namespace 被创建,而且它们的子进程也会被包含到这些 Namespace 中
unshare()将进程移出某个 Namespace
setns()将进程加入到 Namespace 中
1.1、UTS Namespace——主机名和域名
UTS Namespace 是 Linux 提供的一种命名空间(Namespace),它的主要功能是隔离系统的两个标识符:hostname(主机名)和 domainname(域名)。UTS 是指 Unix Time Sharing,来源于 UNIX 系统的时间共享机制,但在这里它主要是命名上的沿用,与时间无关。
在 UTS Namespace 中,每个 Namespace 可以有自己的 hostname 和 domainname。
这意味着:
• 系统中的每个 UTS 命名空间可以拥有独立的主机名和域名。
• 这种隔离使得运行在不同命名空间中的程序认为它们运行在不同的机器上,即使它们实际上在同一个物理主机上运行。
比如:
1. 宿主机的 hostname 是 host1。
2. 创建了一个容器或新 UTS 命名空间,并将 hostname 设置为 container1。
3. 在新命名空间内,所有运行的进程都会认为当前主机名是 container1。
4. 宿主机上的 hostname 和其他命名空间的 hostname 不会受到影响。
下面将使用 Go 来做一个 UTS Namespace 的例子。其实对于 Namespace 这种系统调用,使用 C 语言来描述是最好的,但是本书的目的是去实现 Docker,由于 Docker 就是使用 Go 开发的,所以就整体使用 Go 来讲解。先来看一下如下代码,非常简单。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}exec.Command("sh") 创建了一个新的 shell 进程。然后,通过设置 SysProcAttr 和重定向标准输入、输出和错误流,配置了该进程的属性。最后,通过调用 cmd.Run() 来运行该命令,从而启动新进程
由于 UTS Namespace 对 hostname 做了隔离, 所以在这个环境内修改 hostname 应该不影响外部主机,下面来做一下实验。
在这个 sh 环境内执行如下代码示例 。
hostname -b bird
hostname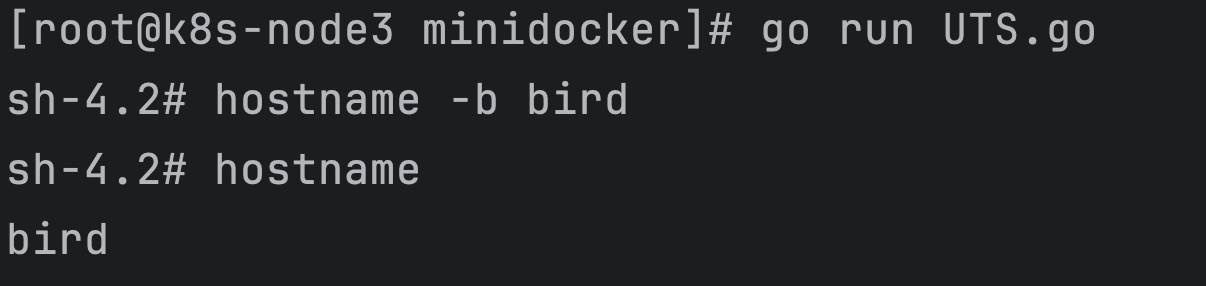
另外启动一个 shell,在宿主机上运行 hostname,看一下效果

可以看到,外部的 hostname 井没有被内部的修改所影响,由此可了解 UTS Namespace 的作用。
1.2、IPC Namespace——进程间通信
PC Namespace 是 Linux 的一种命名空间,用于隔离进程间通信(Inter-Process Communication, IPC)资源。IPC 是指进程之间通过共享内存、消息队列、信号量等机制进行通信的能力,而 IPC Namespace 可以让这些通信资源在不同的命名空间之间互相隔离。
PC Namespace 的作用
在不同的 IPC Namespace 中:
• 每个 Namespace 拥有独立的 IPC 资源(如共享内存段、消息队列、信号量)。
• 不同 Namespace 的 IPC 资源彼此隔离,互相不可见。
• 在同一个 IPC Namespace 中的进程可以共享 IPC 资源。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}可以看到,仅仅增加 syscall.CLONE_NEWIPC 代表我们希望创建 IPC Namespace。
1.3、PID Namespace——进程ID
PID Namespace 是 Linux 提供的一种命名空间,用于隔离进程 ID (PID) 空间。它允许不同的命名空间中有独立的进程 ID,这样可以使得进程在不同的 PID Namespace 中看到的 PID 是不同的,从而实现进程隔离。
PID Namespace 的特点
1. 进程 ID 隔离:
• 不同 PID Namespace 中的进程可以有相同的 PID,但这些 PID 是各自 Namespace 内独立管理的。
• 每个 PID Namespace 有一个“父”命名空间。子命名空间可以看到父命名空间中的进程,但父命名空间无法看到子命名空间的进程。
2. 第一号进程:
• 每个 PID Namespace 中的第一个进程(PID 为 1)通常是一个 init 进程。
• 这个进程负责清理子进程(避免产生孤儿进程),类似于系统中的 init 进程。
3. 嵌套关系:
• PID Namespace 支持嵌套,一个命名空间可以是另一个命名空间的“子”。
• 最顶层的 PID Namespace 是全局的,所有命名空间最终归属于它。
4. 进程隔离:
• 宿主机可以管理和查看所有 PID Namespace 中的进程。
• 子命名空间中的进程只能看到自己命名空间内的进程。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}1.4、Mount Namespace——挂载文件
Mount Namespace 是 Linux 提供的一种命名空间,用于隔离文件系统的挂载点视图。它允许不同的进程组看到不同的文件系统布局,实现文件系统的隔离和定制。
Mount Namespace 的特点
1. 独立的挂载点视图:
• 每个 Mount Namespace 都有独立的挂载点列表,可以为不同的命名空间提供不同的文件系统布局。
• 一个命名空间中的挂载点变动不会影响其他命名空间。
2. 隔离和共享:
• 默认情况下,新命名空间会复制其父命名空间的挂载点(是 共享副本,不是完全隔离)。
• 子命名空间对挂载点的修改(如挂载或卸载)不会影响父命名空间,反之亦然。
3. 层次化:
• Mount Namespace 支持嵌套,父命名空间可以影响子命名空间的初始挂载点,但子命名空间的变更不会反向影响父命名空间。
4. 支持绑定挂载和覆盖:
• 允许为单个目录创建绑定挂载点(bind mount),或在新命名空间中隐藏和重新挂载文件系统(如 chroot)。
Mount Namespace 是 Linux 第 一个实现的 Namespace 类型,因此,它的系统调用参数是 NEWNS ( New Namespace 的缩写)。当时人们貌似没有意识到,以后还会有很多类型的 Namespace 加入 Linux 大家庭。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}1.5、User Namespace——UID和GID
User Namespace 是 Linux 提供的一种命名空间,用于隔离和虚拟化用户和组的权限。它允许在命名空间中为进程指定不同的用户 ID (UID) 和组 ID (GID),使得进程可以以低权限运行,同时在命名空间内被认为是高权限用户(如 root)。
User Namespace 的核心特性
1. UID 和 GID 映射:
• 每个 User Namespace 可以将宿主机的用户 ID 和组 ID 映射为命名空间内的其他 ID。
• 例如,一个在宿主机中 UID 为 1000 的用户,在 User Namespace 中可以被映射为 UID 为 0(即 root)。
2. 权限隔离:
• 在 User Namespace 中,进程可以拥有 root 权限,但这些权限仅限于命名空间内部,不会影响宿主机。
• 这样可以安全地运行需要高权限的任务而不会威胁系统安全。
3. 与其他命名空间协作:
• User Namespace 通常与其他命名空间(如 Mount、PID、Network)结合使用,为容器和隔离环境提供更灵活的权限管理。
4. 嵌套支持:
• User Namespace 支持嵌套,可以在一个命名空间内再创建子命名空间。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS | syscall.CLONE_NEWUSER,
}
cmd.SysProcAttr.Credential = &syscall.Credential{Uid: uint32(1), Gid: uint32(1)}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
os.Exit(-1)
}1.6、Network Namespace——网络
Network Namespace 是用来隔离网络设备、IP 地址端口等网络栈的 Namespace。Network Namespace 可以让每个容器拥有自己独立的(虚拟的)网络设备,而且容器内的应用可以绑定到自己的端口,每个 Namespace 内的端口都不会互相冲突。在宿主机上搭建网桥后,就能很方便地实现容器之间的通信,而且不同容器上的应用可以使用相同的端口 。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWUTS | syscall.CLONE_NEWNS | syscall.CLONE_NEWNET,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
os.Exit(-1)
}执行程序后,使用ifconfig发现没有任何网络设备。
2、Cgroups
Namespace 技术帮助进程隔离出自己单独的空间,但 Docker 是怎么限制每个空间的大小,保证它们不会互相争抢的呢?这就要用到 Linux 的 Cgroups 技术。
Linux Cgroups (Control Groups )提供了对一组进程及将来子进程的资源限制、控制和统计的能力,这些资源包括 CPU 、内存、存储、网络等。通过 Cgroups,可以方便地限制某个进程的资源占用,并且可以实时地监控进程的监控和统计信息。
cgroups(Control Groups) 的三个主要组件分别是:
1、cgroups 实例(Control Groups)
cgroup 是对进程分组管理的一种机制,一个 cgroup 包含一组进程,井可以在这个 cgroup 上增加 Linux subsystem 的各种参数配置,将一组进程和一组subsystem 的系统参数关联起来。
2、子系统(Subsystem)
subsystem 是一组资源控制的模块, 一般包含如下几项 。
blkio 设置对块设备(比如硬盘)输入输出的访问控制
cpu 设置 cgroup 中进程的 CPU 被调度的策略
cpuacct 可以统计 cgroup 中进程的 CPU 占用
cpuset 在多核机器上设置 cgroup 中进程可以使用的 CPU 和内存(此处内存仅使用于 NUMA 架构)
devices 控制 cgroup 中进程对设备的访问
freezer 用于挂起( suspend )和恢复( resume) cgroup 中的进程
memory 用于控制 cgroup 中进程的内存占用
net_els 用于将 cgroup 中进程产生的网络包分类,以便 Linux 的 tc (traffic con位oller )可以根据分类区分出来自某个 cgroup 的包并做限流或监控
net_prio 设置 cgroup 中进程产生的网络流量的优先级
ns 这个 subsystem 比较特殊,它的作用是使 cgroup 中的进程在新的 Namespace 中 fork 新进程 (NEWNS)时,创建出一个新的 cgroup,这个 cgroup 包含新的 Namespace 中的进程 。
每个 subsystem 会关联到定义了相应限制的 cgroup 上,并对这个 cgroup 中的进程做相应的限制和控制。
3、层级(Hierarchy)
hierarchy 的功能是把一组 cgroup 串成一个树状的结构,一个这样的树便是一个 hierarchy,通过这种树状结构,Cgroups 可以做到继承。
比如,系统对一组定时的任务进程通过 cgroup1 限制了 CPU 的使用率,然后其中有一个定时 dump 日志的进程还需要限制磁盘 IO,为了避免限制了磁盘 IO 之后影响到其他进程,就可以创建 cgroup2 ,使其继承于 cgroup1 同时限制磁盘的 IO,这样 cgroup2 便继承了 cgroup1 中对 CPU 使用率的限制,并且增加了磁盘 IO 的限制而不影响到cgroupl 中的其他进程。
三个组件相互的关系
1. 层级 是整体的结构,组织了 cgroups 实例的树状关系。
2. 子系统 为每个层级提供特定的资源管理功能。
3. cgroups 实例 是层级中的具体节点,应用于一组进程。
一个subsystem 只能附加到一个 hierarchy 上面
一个 hierarchy 可以附加多个 subsystem
一个进程可以作为多个 cgroup 的成员,但是这些 cgroup 必须在不同的 hierarchy 中
一个进程 fork 出子进程时,子进程是和父进程在同一个 cgroup 中的,也可以根据需要将其移动到其他 cgroup 中
内核使用 cgroup 结构体来表示一个 control group 对某一个或者某几个 cgroups 子系统的资源限制。cgroup 结构体可以组织成一颗树的形式,每一棵cgroup 结构体组成的树称之为一个 cgroups 层级结构。cgroups层级结构可以 attach 一个或者几个 cgroups 子系统,当前层级结构可以对其 attach 的 cgroups 子系统进行资源的限制。每一个 cgroups 子系统只能被 attach 到一个 cpu 层级结构中。

cgroups层级结构示意图
比如上图表示两个cgroups层级结构,每一个层级结构中是一颗树形结构,树的每一个节点是一个 cgroup 结构体(比如cpu_cgrp, memory_cgrp)。第一个 cgroups 层级结构 attach 了 cpu 子系统和 cpuacct 子系统, 当前 cgroups 层级结构中的 cgroup 结构体就可以对 cpu 的资源进行限制,并且对进程的 cpu 使用情况进行统计。 第二个 cgroups 层级结构 attach 了 memory 子系统,当前 cgroups 层级结构中的 cgroup 结构体就可以对 memory 的资源进行限制。
在每一个 cgroups 层级结构中,每一个节点(cgroup 结构体)可以设置对资源不同的限制权重。比如上图中 cgrp1 组中的进程可以使用60%的 cpu 时间片,而 cgrp2 组中的进程可以使用20%的 cpu 时间片。
package main
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path"
"strconv"
"syscall"
)
// 挂载了memory subsystem的hierarchy的根目录位置
const cgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory"
func main() {
if os.Args[0] == "/proc/self/exe" {
// 容器进程
fmt.Printf("current pid : %d", syscall.Getpid())
fmt.Println()
cmd := exec.Command("sh", "-c", `stress --vm-bytes 200m --vm-keep -m 1`)
cmd.SysProcAttr = &syscall.SysProcAttr{}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
// 在 Linux 系统中,/proc/self/exe 是一个特殊文件,它是当前进程可执行文件的符号链接。
// 通过读取或执行 /proc/self/exe,你可以重新运行当前程序,无需知道它的完整路径。
// 在这里,exec.Command("/proc/self/exe") 意味着运行当前程序的另一个实例(子进程)。
// 在代码中,主程序(父进程)启动了一个新进程(子进程),并将子进程放入隔离环境中(通过 Namespace 和 cgroups)。
// 父进程就是这个go程序,子进程就是这个go程序里面执行exec.Command("/proc/self/exe")后分出来的进程
cmd := exec.Command("/proc/self/exe")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Start(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
} else {
// 得到fork出来的进程映射在外部命名空间的pid
fmt.Printf("%v", cmd.Process.Pid)
// 在系统默认创建挂载了 memory subsystem 的 hierarchy 上创建 cgroup
os.Mkdir(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit"), 0755)
// 将容器进程加入这个 cgroup 中
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "tasks"), []byte(strconv.Itoa(cmd.Process.Pid)), 0644)
// 限制cgroup的使用
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "memory.limit_in_bytes"), []byte("100m"), 0644)
}
cmd.Process.Wait()
}[root@k8s-node3 minidocker]# go run cgroups.go
195414current pid : 1
stress: info: [6] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
stress: FAIL: [6] (415) <-- worker 7 got signal 9
stress: WARN: [6] (417) now reaping child worker processes
stress: FAIL: [6] (421) kill error: No such process
stress: FAIL: [6] (451) failed run completed in 0s
exit status 1
因为已经利用memory子系统限制了这个cgroup的内存上限,所以stress命令去申请内存时,超过了最大值,就不可用了。如果改成申请50M是可以的。
/sys/fs/cgroup/memory 是一个层级
testmemorylimit 是一个 cgroup
pid放入这个cgroup文件就是把这个进程加入了这个cgroup
memory.limit_in_bytes 是 memory 子系统
3、Union File System
Docker的image是由一组layers组合起来得到的,每一层layer对应的是Dockerfile中的一条指令。这些layers中,一层layer为R/W layer,即 container layer,其他layers均为read-only layer,即 Image layer。
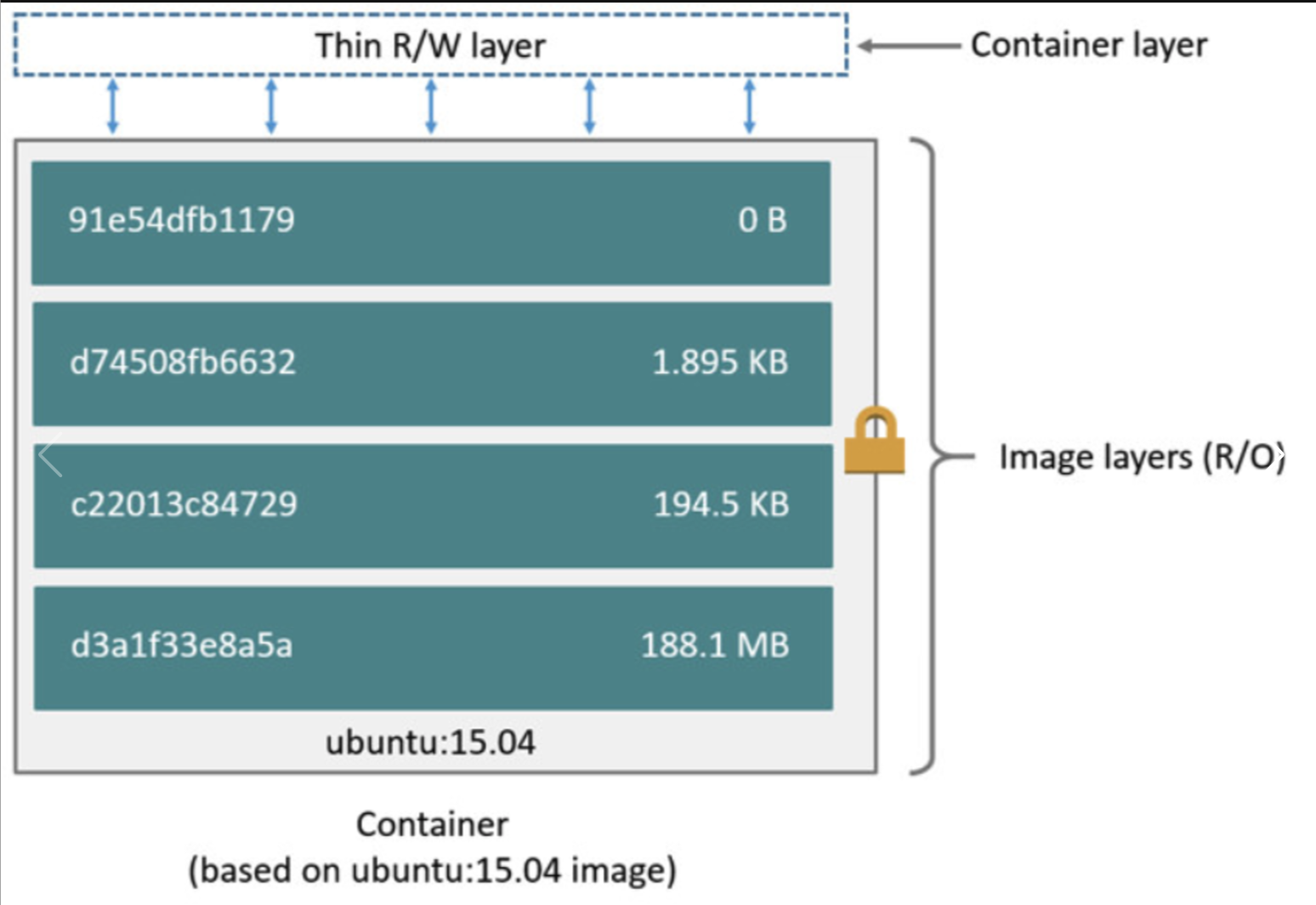
当创建多台容器的时候,我们所有的写操作都是发生在R/W层,其FS结构示意图如下:
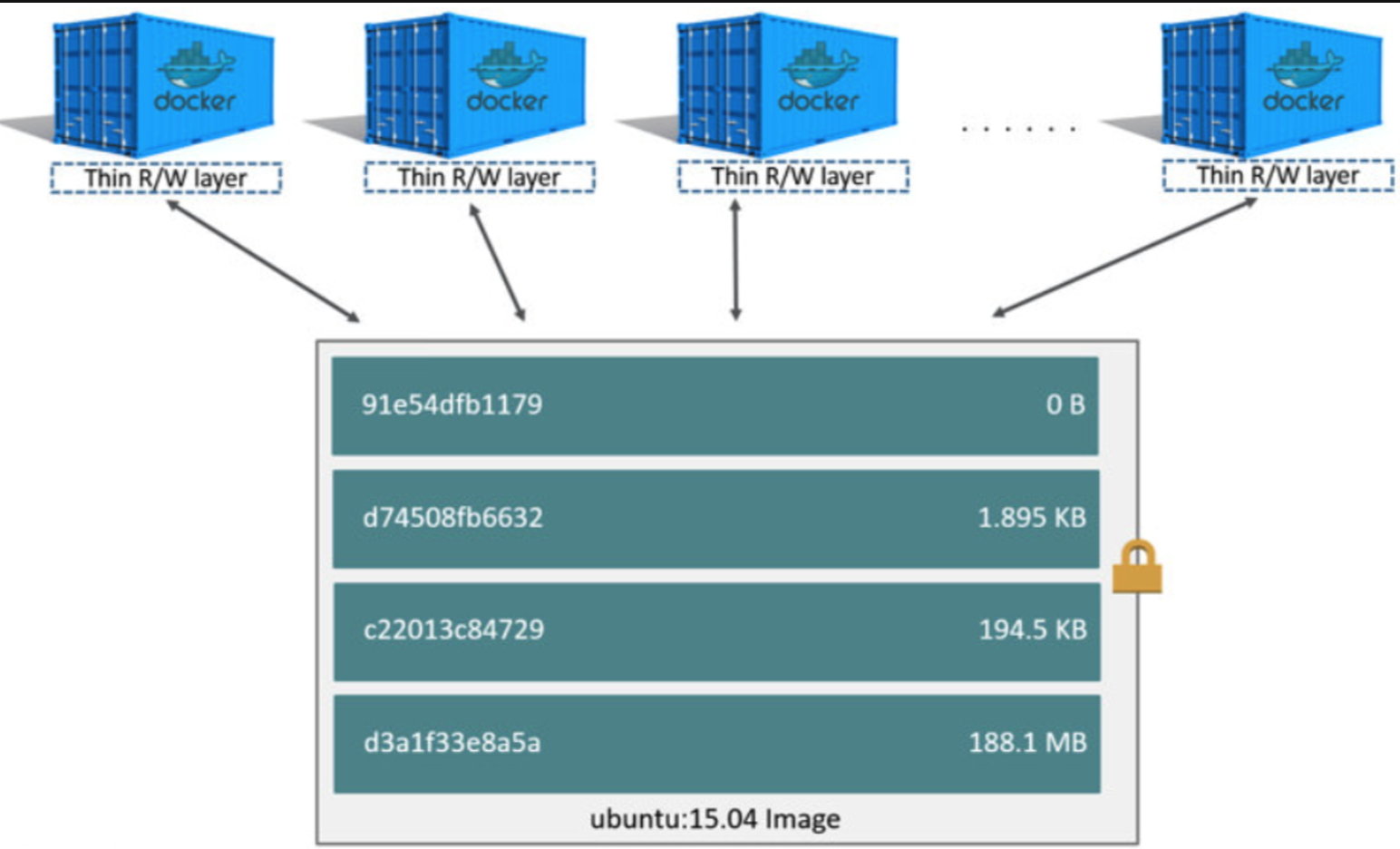
Docker的存储驱动的实现是基于Union File System,简称UnionFS,他是一种为Linux 、FreeBSD 和NetBSD 操作系统设计的,把其他文件系统联合到一个联合挂载点的文件系统服务。它用到了一个重要的资源管理技术,叫写时复制。写时复制(copy-on-write),也叫隐式共享,是一种对可修改资源实现高效复制的资源管理技术。对于一个重复资源,若不修改,则无需立刻创建一个新的资源,该资源可以被共享使用。当发生修改的时候,才会创建新资源。这会大大减少对于未修改资源复制的消耗。Docker基于此去创建images和containers。
AUFS,全称Advanced Multi-Layered Unification Filesystem。AUFS重写了早期的UnionFS 1.x,提升了其可靠性和性能,是早期Docker版本的默认的存储驱动。(Docker-CE目前默认使用OverlayFS)。

AUFS 工作原理,每一个镜像层和容器层都是 /var/lib/docker 下的一个子目录,镜像层和容器层都在 aufs/diff 目录下,每一层的目录名称是镜像或容器的 ID 值,联合挂载点在 aufs/mnt 目录下,mnt 目录是真正的容器工作目录。
下面我们针对 aufs 文件夹下的各目录结构,在创建容器前后的变化做详细讲述。
当一个镜像未生成容器时,AUFS 的存储结构如下。
diff 文件夹:存储镜像内容,每一层都存储在以镜像层 ID 命名的子文件夹中。
layers 文件夹:存储镜像层关系的元数据,在 diif 文件夹下的每个镜像层在这里都会有一个文件,文件的内容为该层镜像的父级镜像的 ID。
mnt 文件夹:联合挂载点目录,未生成容器时,该目录为空。
当一个镜像已经生成容器时,AUFS 存储结构会发生如下变化。
diff 文件夹:当容器运行时,会在 diff 目录下生成容器层。
layers 文件夹:增加容器层相关的元数据。
mnt 文件夹:容器的联合挂载点,这和容器中看到的文件内容一致。mnt 目录下已经出现了我们准备的所有镜像层和容器层的文件(联合挂载了)
Docker 中的 AUFS 工作流程
1. 镜像的构建和存储:
• Docker 镜像存储在多层文件系统中,每一层是一个只读层。
• 当镜像被修改时,Docker 会创建一个新层以记录更改,而不是直接修改原有层。
2. 容器启动:
• 容器启动时,Docker 会将镜像的所有只读层叠加起来,同时添加一个可写层(container layer)到顶部。
• AUFS 负责将这些层联合挂载为一个虚拟文件系统。
3. 文件读写操作:
• 读取文件: AUFS 从上到下查找文件,找到后返回文件内容。
• 写入文件: 如果文件在只读层,AUFS 会将文件复制到可写层,然后写入数据。
• 删除文件: AUFS 创建一个白标文件,表示文件在上层已被删除。
创建AUFS:
mount 是一个非常强大的命令,我们可以用它来创建 AUFS 文件系统。下面的命令把 container-layer、image-layer1、image-layer2、image-layer3 以 AUFS 的方式挂载到刚才创建的 mnt 目录下:
mount -t aufs -o dirs=./container-layer:./image-layer1:./image-layer2:./image-layer3 none ./mnt注意,在 mount 命令中我们没有指定要挂载的 4 个文件夹的权限信息,其默认行为是:dirs 指定的左边起第一个目录是 read-write 权限,后续目录都是 read-only 权限。我们可以通过下面的方式查看详情:
4、Linux proc 文件系统介绍
Linux 下的 /proc 文件系统是由内核提供的,它其实不是一个真正的文件系统,只包含了系统运行时的信息(比如系统内存、mount 设备信息、一些硬件配置等),它只存在于内存中,而不占用外存空间。它以文件系统的形式,为访问内核数据的操作提供接口。实际上,很多系统工具都是简单地去读取这个文件系统的某个文件内容,比如lsmod,其实就是cat /proc/modules 。
当遍历这个目录的时候,会发现很多数字,这些都是为每个进程创建的空间,数字就是它们的 PID 。
进入进程对应的文件夹后,可以看到有很多文件。

每一个文件都是对应进程的一些信息



