

Go规范
1、包命名
在给包命名时不需要考虑重复的问题,因为导入路径不一样。
包名一般采用小写形式的单个单词命名
包名应尽量与包导入路径的最后一个路径分段保持一致
不仅要考虑包自身的名字,还要兼顾该包的标识符(如变量、常量、函数等)的命名。由于用这些标识符时需要加入包名作为前缀,因此在对这些标识符命名时就不要再包含包名了。
strings.Reader [good]
strings.StringReader [bad]
strings.NewReader [good]
strings.NewStringReader [bad]
bytes.Buffer [good]
bytes.ByteBuffer [bad]
bytes.NewBuffer [good]
bytes.NewByteBuffer [bad]Go源码文件头部的包导入语句中import后面的部分是一个路径,路径的最后一个分段是目录名,而不是包名;
包名和路径的最后一段是可以不一样的。import后面的东西,是路径,而不是包名。
例如import a/b/c,但是c里面的go文件属于包d。abc都是路径,具体使用函数时使用包d。
Go编译器的包源码搜索路径由基本搜索路径和包导入路径组成,两者结合在一起后,编译器便可确定一个包的所有依赖包的源码路径的集合,这个集合构成了Go编译器的源码搜索路径空间;
同一源码文件的依赖包在同一源码搜索路径空间下的包名冲突问题可以由显式指定包名的方式解决。
2、变量、函数命名
Go语言官方要求标识符命名采用驼峰命名法(CamelCase),以变量名为例,如果变量名由一个以上的词组合构成,那么这些词之间紧密相连,不使用任何连接符(如下划线)
驼峰命名法有两种形式:一种是第一个词的首字母小写,后面每个词的首字母大写,叫作“小骆峰拼写法”(lowerCamelCase),这也是在Go中最常见的标识符命名法;而第一个词的首字母以及后面每个词的首字母都大写,叫作“大驼峰拼写法”(UpperCamelCase),又称“帕斯卡拼写法”(PascalCase)。由于首字母大写的标识符在Go语言中被视作包导出标识符,因此只有在涉及包 导出的情况下才会用到大驼峰拼写法。
如果缩略词的首字母是大写的,那么其他字母也要保持全部大写,比如HTTP(Hypertext Transfer Protocol)、CBC(Cipher Block Chaining)等
除了上述特征,还有一些在命名时常用的惯例。
(1)变量名字中不要带有类型信息
userSlice []*User [bad]
users []*User [good]带有类型信息的命名只是让变量看起来更长,并没有给开发者阅读代码带来任何好处。
(2)保持简短命名变量含义上的一致性
这里大致分析一下Go标准库中常见短变量名字所代表的含义,这些含义在整个标准库范畴内的一致性保持得很好。
变量v、k、i的常用含义:
// 循环语句中的变量
for i, v := range s { ... } // i为下标变量; v为元素值
for k, v := range m { ... } // k为key变量; v为元素值
for v := range r { // channel ... } // v为元素值
// if、switch/case分支语句中的变量
if v := mimeTypes[ext]; v != "" { } // v: 元素值
switch v := ptr.Elem(); v.Kind() {
...
}
case v := <-c: // v: 元素值
// 反射的结果值
v := reflect.ValueOf(x)
变量t的常用含义:
t := time.Now() // 时间
t := &Timer{} // 定时器
if t := md.typemap[off]; t != nil { } // 类型
变量b的常用含义:
b := make([]byte, n) // byte切片
b := new(bytes.Buffer) // byte缓存i——下标(index)
k——键(key)
v——值(value)
t——时间(time)
b——字节(byte)
3、常量命名
在C语言家族中,常量通常用全大写的单词命名。
但在Go语言中,常量在命名方式上与变量并无较大差别,并不要求全部大写。只是考虑其含义的准确传递,常量多使用多单词组合的方式命名。下面是标准库中的例子:
const (
deleteHostHeader = true
keepHostHeader = false
)当然,可以对名称本身就是全大写的特定常量使用全大写的名字, 比如数学计算中的PI,或是为了与系统错误码、系统信号名称保持一致 而用全大写方式命名:
// 信号
const (
SIGABRT = Signal(0x6)
SIGALRM = Signal(0xe)
SIGBUS = Signal(0x7)
SIGCHLD = Signal(0x11) ...
)在Go中数值型常量无须显式赋予类型,常量会在使用时根据左值类型和其他运算操作数的类型进行自动转换,因此常量的名字也不要包含类型信息。
4、接口命名
在Go语言中,对于接口类型优先以单个单词命名。对于拥有唯一方法 (method)或通过多个拥有唯一方法的接口组合而成的接口,Go语言的惯例是用“方法名+er”命名。比如:

Go语言推荐尽量定义小接口,并通过接口组合的方式构建程序。
5、短变量声明
包级的变量声明只能使用var声明,而不能使用短变量声明。只有局部变量可以使用短变量声明。
尽量在分支控制时应用短变量声明形式,这样的应用方式体现出“就近原则”,让变量的作用域最小化了。
6、无类型常量
绝大多数情况下,Go常量在声明时并不显式指定类型,也就是说使用的是无类型常量(untyped constant)
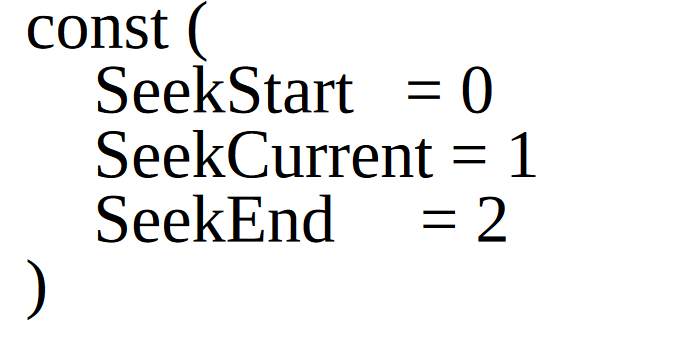
Go是对类型安全要求十分严格的编程语言。Go要求,两个类型即便拥有相同的底层类型,也仍然是不同的数据类型,不可以被相互比较或混在一个表达式中进行运算:

可以发现go是不支持隐式类型转换的,必须是显式类型转换

这是显式声明带来的问题。
使用隐式常量声明时就可以不用显式类型转换了:

无类型常量是Go语言推荐的实践,它拥有和字面值一样的灵活特性,可以直接用于更多的表达式而不需要进行显式类型转换,从而简化了代码编写。
7、零值可用
对于C语言中,如果只是声明变量而不进行初始化,那么这个变量是不可以使用的。
//n的值是不确定的
void f() {
int n;
printf("local n = %d\n", n);
if (cnt > 5) {
return;
}
cnt++;
f();
}但是对于Go,如果不进行初始化,会默认赋零值。
所有整型类型:0
浮点类型:0.0
布尔类型:false
字符串类型:""
指针、interface、切片(slice)、channel、map、 function:nil
对于零值变量,是可以直接使用的

我们先来看看sync.Mutex。
在C语言中,要使用线程互斥锁,我们 需要这么做:
pthread_mutex_t mutex; // 不能直接使用 // 必须先对mutex进行初始化
pthread_mutex_init(&mutex, NULL); // 然后才能执行lock或unlock
pthread_mutex_lock(&mutex);
pthread_mutex_unlock(&mutex);
但是在Go语言中,我们只需这么做:
var mu sync.Mutex
mu.Lock()
mu.Unlock()Go语言零值可用的理念给内置类型、标准库的使用者带来很多便利。不过Go并非所有类型都是零值可用的,并且零值可用也有一定的限 制,比如:在append场景下,零值可用的切片类型不能通过下标形式操作数据:
var s []int
s[0] = 12 // 报错!
s = append(s, 12) // 正确另外,像map这样的原生类型也没有提供对零值可用的支持:
var m map[string]int
m["go"] = 1 // 报错!
m1 := make(map[string]int)
m1["go"] = 1 // 正确另外零值可用的类型要注意尽量避免值复制:
var mu sync.Mutex
mu1 := mu // 错误: 避免值复制
foo(mu) // 错误: 避免值复制
var mu sync.Mutex
foo(&mu) // 正确8、指针
在 C 和 C++ 中,. 用于访问结构体的字段,-> 用于访问结构体指针的字段。
但在 Go 中,无论我们的变量是一个结构体还是一个结构体指针,我们都使用 . 来访问其字段。
这样做的好处是,代码更简洁,更易于阅读和编写。你不需要关心一个变量是结构体还是结构体的指针,都可以使用同样的方式来访问其字段。这也使得在函数间传递结构体和结构体指针时,代码的改动更小。
9、方法
方法的receiver类型是值还是指针类型选择,需要考虑三个方面:
(1)方法的本质
方法的本质就是以receiver为第一个参数的普通函数。
var t T
func (t T) get()
就相当于
func get(t T)所以receiver是值类型还是指针类型是有影响的。
type T struct {
a int
}
func (t T) M1() {
t.a = 10
}
func (t *T) M2() {
t.a = 11
}
func main() {
var t T
println(t.a) //0
t.M1()
println(t.a) //0
t.M2()
println(t.a) //11
}
//答案是0 0 11方法绑定的receiver类型会引起值传递还是指针传递
这里就和值传递和指针传递一样。
根据方法的本质,如果receiver是值类型,那么就相当于这个方法的第一个参数是值传递,改变的是一个拷贝副本,而不是真实值。形参修改不会影响到实参。
如果reveiver是指针类型,那么就是指针传递,形参修改会影响实参。
如果要对类型实例进行修改,那么为receiver选择*T类型。
如果没有对类型实例修改的需求,那么为receiver选择T类 型或*T类型均可;但考虑到Go方法调用时,receiver是以值复制的形式传入方法中的,如果类型的size较大,以值形式传入会导致较大损耗,这时选择*T作为receiver类型会更好些。
(2)自动转换
Go语法糖使得我们在通过类型实例调用类型方法时无须考虑实例类型与receiver参数类型是否一致,编译器会为我们做自动转换。
type T struct {
a int
}
func (t T) M1() {
t.a = 10
}
func (t *T) M2() {
t.a = 11
}
func main() {
t.M1() //1
t.M2() //2
}虽然t是T类型,但是在M1和M2方法调用时,会自动做类型转化,变为*T。
(3)方法和接口的交互
type Interface interface {
M1()
M2()
}
type T struct{}
func (t T) M1() {}
func (t *T) M2() {}
func main() {
var t T
var pt *T
var i Interface
i = t
i = pt
}
//运行程序不通过。编译器给出的错误信息是:不能 使用变量t给接口类型变量i赋值,因为t没有实现Interface接口方法集合 中的M2方法在上述代码中,t没有实现M2方法,但是pt却实现了M1和M2方法。因此可以把M2给i。
为什么呢?
Go语言规范:对于非接口类型的自定义类型T,其方法集合由所有receiver为T类型的方法组成;而类型*T的方法集合则包含所有receiver为T和*T类型的方法
到这里,我们完全明确了为receiver选择类型时需要考虑的第三因素:是否支持将T类型实例赋值给某个接口类型变量。如果需要支持,我们就要实现receiver为T类型的接口类型方法集合中的所有方法。
10、变长参数函数
顾名思义,变长参数函数就是指调用时可以接受零个、一个或多个实际参数的函数,就像下面对fmt.Println的调用。
func Println(a ...interface{}) (n int, err error)我们看到,无论传入零个、两个还是多个实际参数,这些实参都传 给了Println的形式参数a。形参a的类型是一个比较奇特的组合:... interface{}。这种接受“...T”类型形式参数的函数就被称为变长参数函数。
一个变长参数函数只能有一个“...T”类型形式参数,并且该形式参数应该为函数参数列表中的最后一个形式参数。
变长参数函数的“...T”类型形式参数在函数体内呈现为[]T类型的变量,我们可以将其理解为一个Go语法糖:
func sum(args ...int) int {
var total int // 下面的args的类型为[]int
for _, v := range args {
total += v
}
return total
}在函数外部,“...T”类型形式参数可匹配和接受的实参类型有两种:
多个T类型变量
t...(t为[]T类型变量)
func main() {
a, b, c := 1, 2, 3
println(sum(a, b, c)) // 传入多个int类型的变量
nums := []int{4, 5, 6}
println(sum(nums...)) // 传入"nums...",num为[]int型变量
}注意这里有个问题,这里传入的是T类型切片+...,而不只是切片
T类型切片加...——后面的...是告诉函数,传入的切片是多个参数的集合,而不是一个参数。
T类型切片——传入的就是一个参数,而这个参数就是一个切片
func dump(args ...interface{}) {
for _, v := range args {
fmt.Println(v)
}
}
//传入切片,不加...
func main() {
s := []interface{}{"Tony", "John", "Jim"}
dump(s)
}
//输出
[Tony John Jim]//传入切片+...
func main() {
s := []interface{}{"Tony", "John", "Jim"}
dump(s...)
}
//输出
Tony
John
Jim 从上面两个传入的不同可以发现,有没有...是有区别的,没有...就是传入一个参数,这个参数就是一个切片整体,所以循环只做一次,直接prinln这个切片。
有...传入的是多个参数,循环做三次,每次取一个切片里面的元素。
但我们只能选择上述两种实参类型中的一种:要么是多个T类型变量,要么是t...(t为[]T类型变量)。如果将两种混用,则会得到类似下 面的编译错误:
println(sum(a, b, c, nums...)) // 调用sum函数时传入太多参数使用变长参数函数时最容易出现的一个问题是实参与形参不匹配, 比如下面这个例子:
func dump(args ...interface{}) {
for _, v := range args {
fmt.Println(v)
}
}
func main() {
s := []string{"Tony", "John", "Jim"}
dump(s...)
}
//这里是想把[]string 变成[]interface{}编译器给出了“类型不匹配”的错误。
dump函数的变长参数类型为“...interface{}”,因此匹配该形参的要么是interface{}类型的变量,要么为“t...”(t类型为[]interface{})。在例子中给dump传入的实参为“s...”,但s的类型为[]string,并非[]interface{},导致不匹配。这里 要注意的是,虽然string类型变量可以直接赋值给 interface{}类型变 量,但是[]string类型变量并不能直接赋值给 []interface{}类型变量。
将代码改为:
func main() {
s := []interface{}{"Tony", "John", "Jim"}
dump(s...)
}
//这里是把Tony这种string转换为了interface{}
//输出
Tony
John
Jim //或者是s没有...
func main() {
s := []string{"Tony", "John", "Jim"}
dump(s)
}
//输出
[Tony John Jim]上面的实例说明了:
string -> interface{}
[]string -> interface{}
[]string 不可以-> []interface{}
变长参数核心就是,func (t...T),传入参数有两种形式:
多个T类型变量
一个t...,t是[]T类型
11、继承
当多个结构体具有相同的属性和方法使,可以从这些结构体抽象出结构体,在该结构体中定义这些相同的熟悉和方法,其他的结构体就不需要重新定义这些熟悉和方法了,只需嵌套一个匿名结构体即可。
就是说,在Go中,如果一个struct嵌套了另一个匿名结构体,那么这个struct可以直接访问匿名结构体的字段和方法,从而实现了继承。
//定义基类Animal
type Animal struct {
Age int
Weight float32
}
//给Animal绑定方法
func (an *Animal) Shout() {
fmt.Println("我可以大叫")
}
//定义结构体:cat
type Cat struct {
Animal
}
//对cat绑定特有的方法
func (c *Cat) scratch() {
fmt.Println("我是猫,我可以挠人")
}
func main() {
cat := Cat{}
cat.Animal.Age = 3
cat.Animal.Weight = 10.6
cat.Shout()
cat.scratch()
}如果嵌套的匿名结构体具有相同的字段或方法名,则在访问时,需要通过匿名结构体类型名来区分。
12、多态
变量具有多种形态,面向对象的第三大特征,在Go语言中,多态是通过接口实现的,可以按照统一的接口来调用不同的实现,这时接口变量就呈现不同的形态。
//定义了一个函数叫say,传入参数是一个接口。
func say(c communication) {
c.sayHello()
}
//具体传入的是一个实现了这个接口的类型,不同的类型实现这个接口的不同就是多态
func main() {
c := chinese{
name: "wuyq",
}
u := usa{
name: "David",
}
say(c)
say(u)
}13、test
test文件命名是原本的文件名加_test.go,例如add.go对应的test文件名是add_test.go
test函数的命名一般是函数名前加Test。
例如Add函数的测试叫TestAdd。
如果Add函数属于一个叫Manager的接受者,那么测试函数叫TestManager_Add。
子测试
在一个测试函数里面有很多的测试用例:利用t.Run
// calc_test.go
func TestMul(t *testing.T) {
cases := []struct { // 通过定义一个结构体来保存多个测试用例
Name string // 这里有一个name,来表示这一条测试用例代表了什么
A, B, Expected int
}{
{"pos", 2, 3, 6},
{"neg", 2, -3, -6},
{"zero", 2, 0, 0},
}
for _, c := range cases { // 因为有很多测试用例,所以需要for循环遍历
t.Run(c.Name, func(t *testing.T) { // 使用t.Run来进行子测试
if ans := Mul(c.A, c.B); ans != c.Expected {
// t.Error/t.Errorf 和t.Fatal/t.Fatalf区别是前者遇错不停会继续向下,后者直接停下
t.Fatalf("%d * %d expected %d, but %d got",
c.A, c.B, c.Expected, ans)
}
})
}
}