

k8s八股相关
0、创建Pod的过程
第一步:kubectl create pod
首先进行认证(RBAC方式 或者 key方式进行认证 )后获得具体的权限,然后kubectl会调用master api创建对象的接口,然后向k8s apiserver发出创建pod的命令
第二步:k8s apiserver
apiserver收到请求后,并非直接创建pod,而是先创建一个包含pod创建信息的yaml文件,并将文件信息写入到etcd中(如果此处是用yaml文件创建pod,则这两步就可以忽略)
创建pod形式有二种方案。一种是通过api直接创建生成yaml,另外一种是通过yaml直接应用。
第三步:controller manager
创建Pod的yaml信息会交给controller manager ,controller manager根据配置信息将要创建的资源对象(pod)放到等待队列中。
第四步:scheduler
kube-scheduler(调度器)通过 List-Watch 机制(持续监听 API Server 中资源的变化),发现 “未调度(nodeName: null)” 的 Pod 后,会执行调度算法(综合节点资源、亲和性等因素),为 Pod 分配一个合适的节点(例如将 nodeName 设为 worker-01),并将 “Pod 与节点的绑定信息” 同步至 etcd(集群的配置存储中心)。
第四步:kubelet
目标节点上的 kubelet,同样通过 List-Watch 机制,发现 “已绑定到本节点” 的 Pod 后,会调用 Containerd(容器运行时,负责容器的生命周期管理),依次执行以下操作:
运行 Pod 沙箱(RunPodSandbox):为 Pod 创建独立的网络和存储环境(沙箱是 Pod 内所有容器共享的基础环境)。
拉取镜像(PullImage):从镜像仓库拉取 Pod 运行所需的容器镜像。
创建并启动容器(CreateContainer、StartContainer):基于拉取的镜像,创建容器并启动运行。
网络插件配置网络:Containerd 会调用 CNI(容器网络接口) 网络插件,为 Pod 完成网络配置,比如分配唯一 IP 地址、设置网络路由等,确保 Pod 能与集群内其他组件通信。
第五步:controller manager
controller manager会通过API Server提供的接口实时监控资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将其状态修复到“期望状态”。
1、创建 Deployment 会发生什么
启动整个流程之前,控制器、调度器、 Kubelet就已经通过API 服务器监听它们各自资源类型的变化了。图中不包含 etcd, 因为它被隐藏在 API 服务器之后,可以想象成 API服务器就是对象存储的地方。
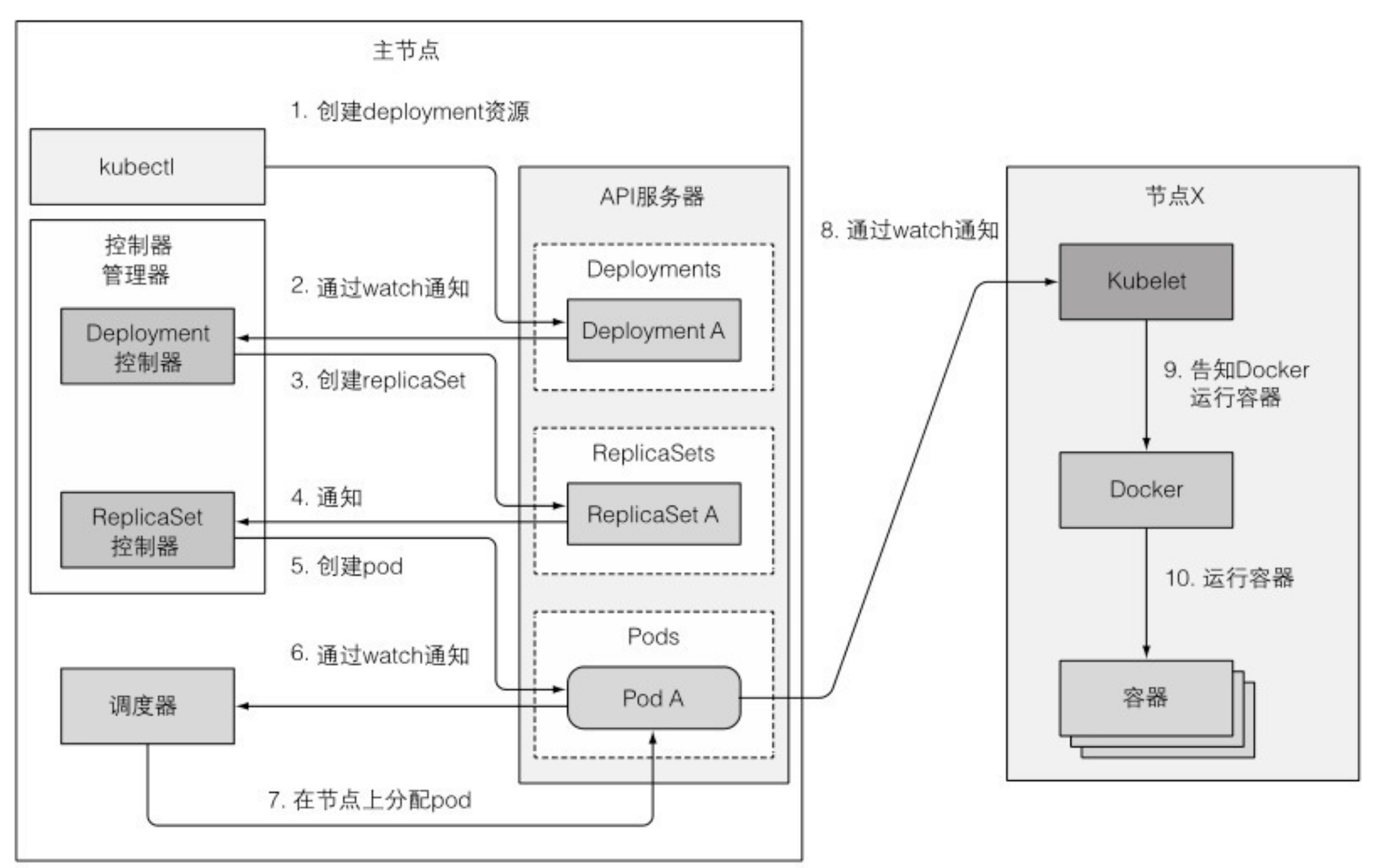
deployment资源的创建
准备包含 Deployment 清单的 YAML文件,通过 kubetctl 提交到 Kubernetes。kubectl通过HTTP POST请求发送清单到 Kubernetes API服务器。 API 服务器检查 Deployment 定义,存储到 etcd ,返回响应给 kubectl。
除了pod需要拉镜像运行,其他资源把资源文件存入etcd就是创建了。
Deployment控制器生成ReplicaSet
当新创建 Deployment资源时,所有通过 API 服务器监听机制监听 Deployment 列表的客户端马上会收到通知。其中有个客户端叫 Deployment控制器。
控制平面的 controller manager 里面有很多的控制器,像:
ReplicationController控制器
ReplicaSet控制器
DaemonSet控制器
Job控制器
Deployment 控制器
StatefulSet 控制器
Node 控制器
Service控制器
Endpoints控制器
Namespace 控制器
PersistentVolume 控制器。
这些控制器负责管理对应资源,包括创建、更新、删除。
一个 Deployment由一个或多个 Replicaset 支持,ReplicaSet 后面会创建实际的pod。controller manager里面的 Deployment 控制器跟API server交互时检查到有一个新的 Deployment 对象时,会按照 Deploymnet 当前定义创建 ReplicaSet。这包括通过 Kubernetes API创建一个新的 ReplicaSet资源。 Deployment控制器完全不会去处理单个pod。
ReplicaSet控制器创建pod资源
新创建的 ReplicaSet由ReplicaSet控制器(通过 API服务器创建、修改、删除ReplicaSet资源)接收。控制器会考虑 replica数量、ReplicaSet 中定义的pod选择器,然后检查是否有足够的满足选择器的pod。
然后控制器会基于 ReplicatSet 的 pod 模板创建 pod 资源(当 Deployment控制器创建ReplicaSet时,会从Deployment复制pod模板)。
调度器分配节点给新创建的pod
新创建的 pod目前保存在 etcd中,但是它们每个都缺少一个重要的东西 ——它们还没有任何关联节点。它们的 nodeName 属性还未被设置。调度器会监控像这样的 pod,发现一个,就会为 pod选择最佳节点,并将节点分配给 pod。pod的定义现在就会包含它应该运行在哪个节点。
目前,所有的一切都发生在 Kubernetes 控制平面中。参与这个全过程的控制器没有做其他具体的事情,除了通过API服务器更新资源。
Kubelet运行pod容器
随着pod目前分配给了特定的节点,节点上的 Kubelet 终于可以工作了。Kubelet通过API服务器监听pod变更,发现有新的pod分配到本节点后,会去检查pod定义,然后命令 Docker 或者任何使用的容器运行时来启动pod容器,容器运行时就会去运行容器。
2、探针
存活探针(liveness probe)
k8s可以通过存活探针,检查容器是否还在运行。可以为pod中每个容器单独指定存活探针,如果探测失败,k8s将定期执行探针并重新启动容器。
Kubernetes 存活探针有以下三种探测容器的机制:
HTTP GET探针对容器的 IP 地址(你指定的端又和路径)执行 HTTP GET请求。如果探测器收到响应,并且响应状态码不代表错误 (换句话说,如果 HTTP响应状态码是2xx或3xx),则认为探测成功。 如果服务器返回错误响应状态码或者根本没有响应,那么探测就被认为是失败的,容器将被重新启动。
TCP套接字探针尝试与容器指定端又建立 TCP连接。如果连接成功建立,则探测成功。否则,容器重新启动。
Exec探针在容器内执行任意命令,并检查命令的退出状态码。如 果状态码是0,则探测成功。所有其他状态码都被认为失败。
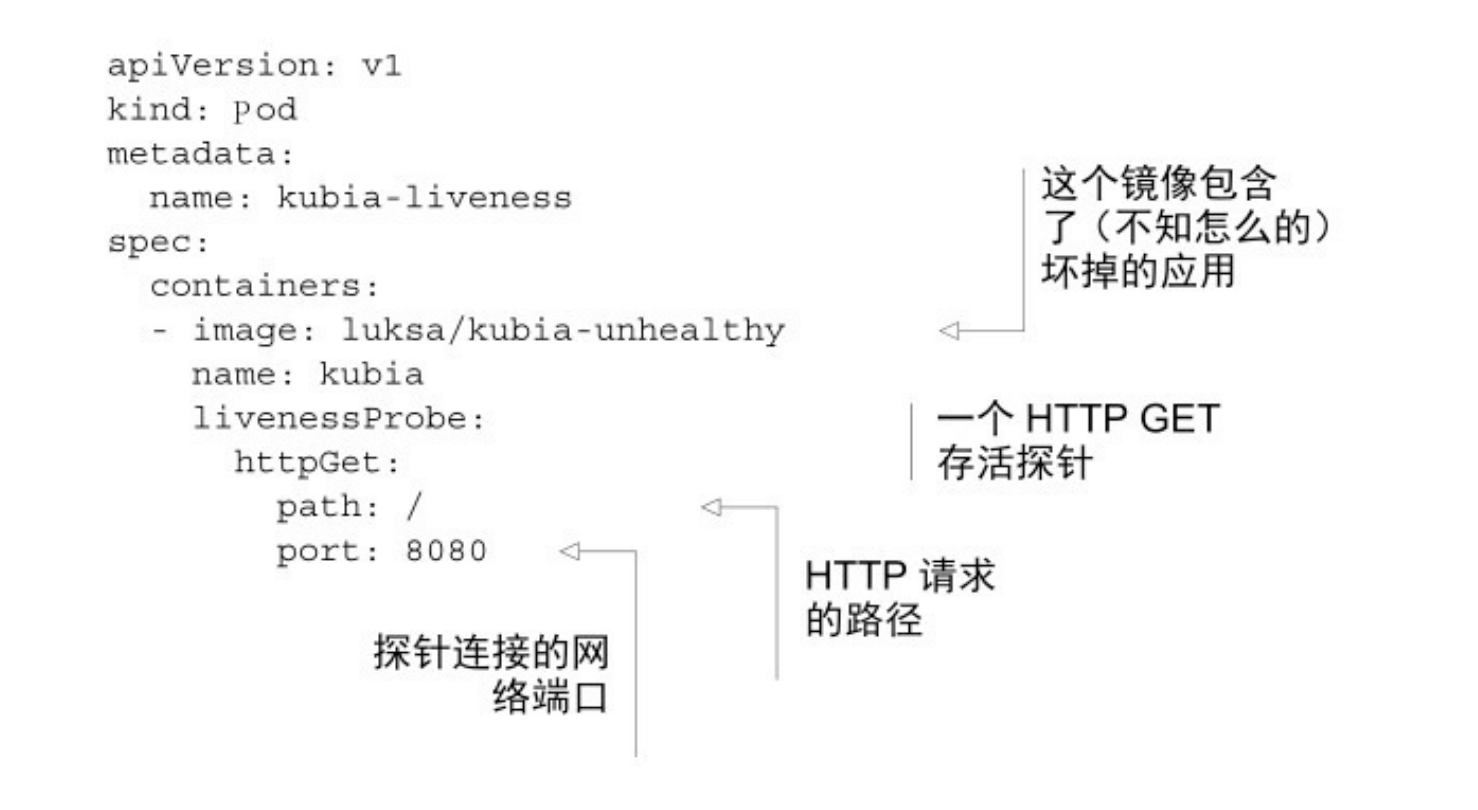
该 pod 的描述文件定义了一个 httpGet 存活探针,该探针告诉 Kubernetes定期在端口8080路径上执行 HTTP GET请求,以确定该容器是否健康。这些请求在容器运行后立即开始。
当你想知道为什么前一个容器终止时,你想看到的是前一个容器的日志,而不是当前容器的。可以通过添加--previous选项来完成:
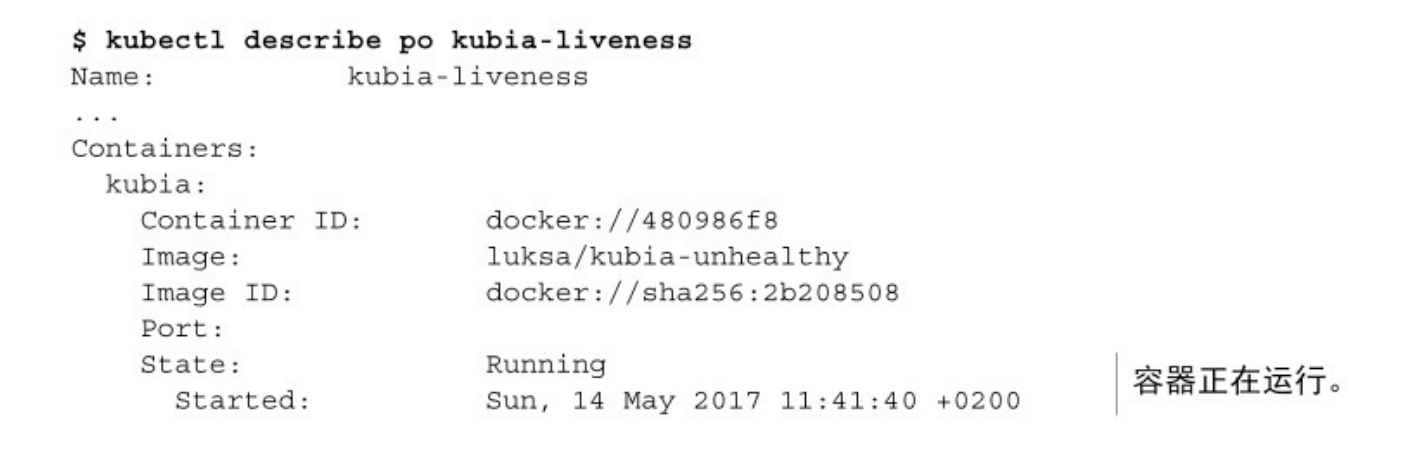
kubectl logs mypod --previous可以通过查看kubectl describe的内容来了解为什么必须重启容器, 如下面的代码清单所示
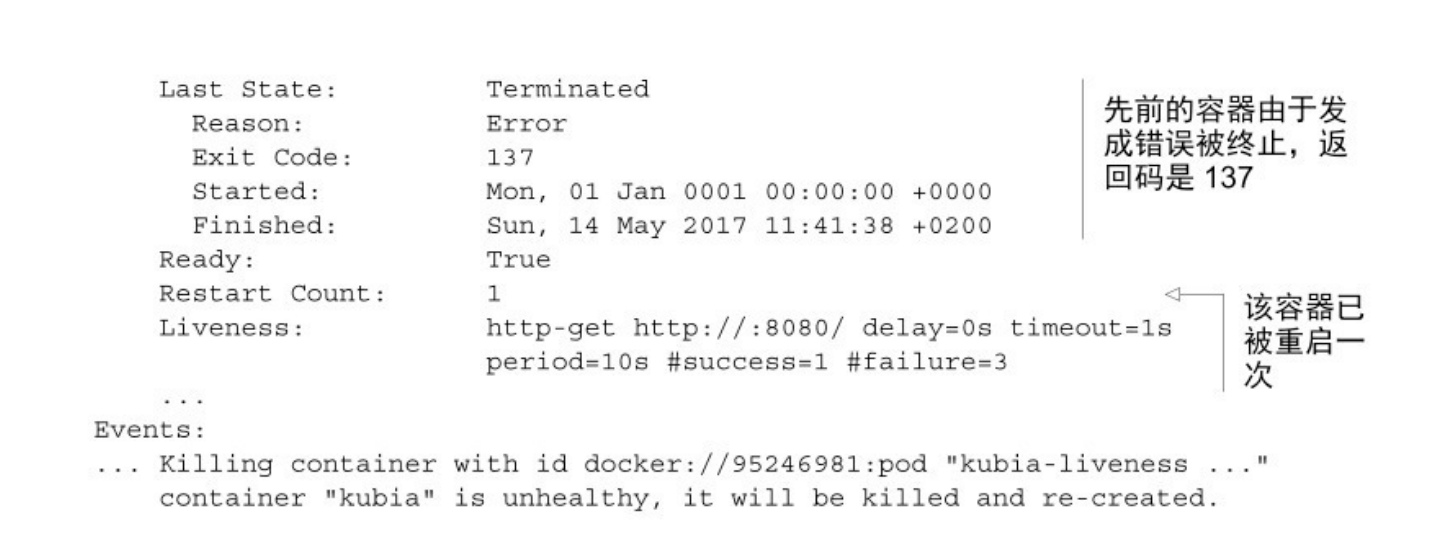
在底部列出的事件显示了容器为什么终止 ——Kubernetes发现容器 不健康,所以终止并重新创建。
kubectl describe 还显示关于存活探针的附加信息:

除了明确指定的存活探针选项,还可以看到其他属性,例如 delay(延迟)、 timeout(超时)、 period(周期)等。delay=0s部分显示在容器启动后立即开始探测。 timeout仅设置为1秒,因此容器必须 1 秒内进行响应,不然这次探测记作失败。每 10 秒探测一次容器 (period=10s),并在探测连续三次失败(#failure=3)后重启容器。
定义探针时可以自定义这些附加参数。例如,要设置初始延迟, 将 initialDelaySeconds 属性添加到存活探针的配置中。
如果没有设置初始延迟,探针将在启动时立即开始探测容器,这 通常会导致探测失败,因为应用程序还没准备好开始接收请求。如果 失败次数超过阈值,在应用程序能正确响应请求之前,容器就会重启。
就绪探针(readiness probe)
像存活探针一样,就绪探针有三种类型:
Exec探针,执行进程的地方。容器的状态由进程的退出状态代码确定。
HTTP GET探针,向容器发送 HTTP GET请求,通过响应的 HTTP 状态代码判断容器是否准备好。
TCP socket探针,它打开一个 TCP 连接到容器的指定端口。如果连接已建立,则认为容器已准备就绪。
启动容器时,可以为 Kubernetes配置一个等待时间,经过等待时间后才可以执行第一次准备就绪检查。之后,它会周期性地调用探针, 并根据就绪探针的结果采取行动。如果某个 pod报告它尚未准备就绪, 则会从该服务中删除该pod。如果pod再次准备就绪,则重新添加pod。
与存活探针不同,如果容器未通过准备检查,则不会被终止或重新启动。这是存活探针与就绪探针之间的重要区别。存活探针通过杀死异常的容器并用新的正常容器替代它们来保持 pod 正常工作,而就绪探针确保只有准备好处理请求的 pod 才可以接收它们(请求)。这在容器启动时最为必要,当然在容器运行一段时间后也是有用的。
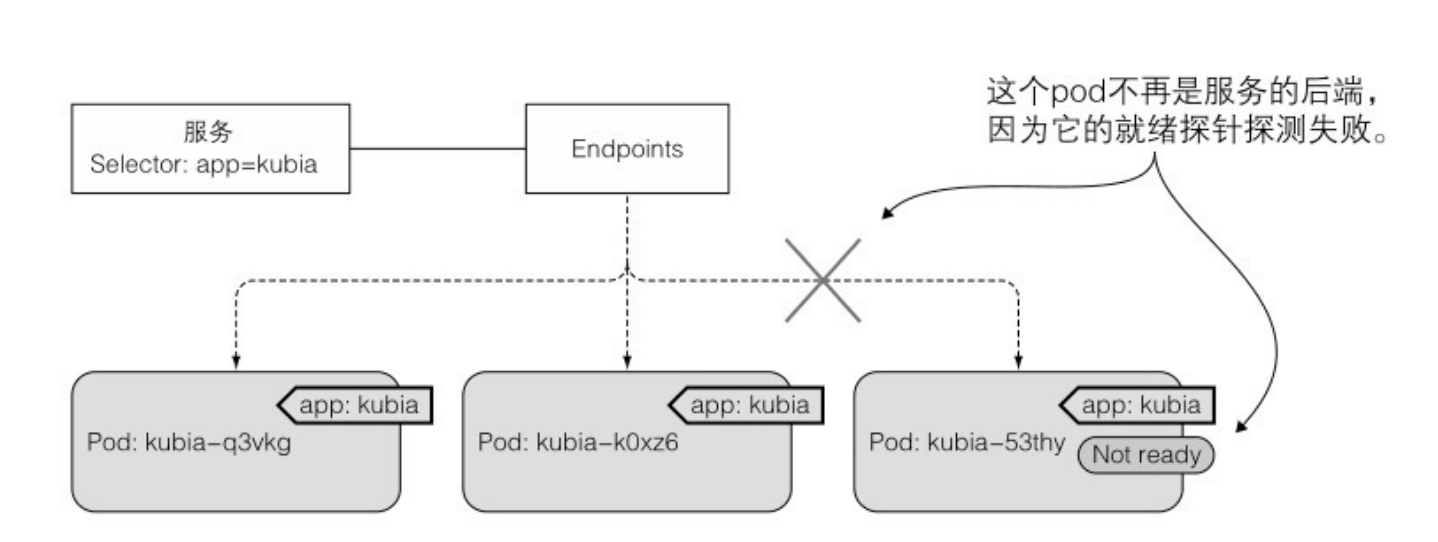
如果一个容器的就绪探测失败,则将该容器从 endpoint 对象中移除。连接到该服务的客户端不会被重定向到 pod。这和 pod 与 service 的标签选择器完全不匹配的效果相同。
可以通过 kubectl edit 命令来向已存在的 ReplicationController中的 pod 模板添加探针。

就绪探针将定期在容器内执行 ls/var/ready命令。如果文件存在,则 ls命令返回退出码 0,否则返回非零的退出码。如果文件存在,则就绪探针将成功;否则,它会失败。
观察并修改pod就绪状态

READY列显示出没有一个容器准备好。现在通过创建 /var/ready文 件使其中一个文件的就绪探针返回成功,该文件的存在可以模拟就绪探针成功:

使用kubectl exec命令在kubia-2r1qb的pod容器内执行touch命令。如果文件尚不存在, touch命令会创建该文件。就绪探针命令现在应该返回退出码 0,这意味着探测成功,并且现在应该显示 pod 已准备就绪。 现在去查看其状态:

准备就绪探针会定期检查——默认情况下每 10秒检查一次。由于尚未调用就绪探针,因此容器未准备好。但是最晚10秒钟内,该pod应该已经准备就绪,其 IP 应该列为 service 的 endpoint。
3、service是什么
和 Service 相关的任何事情都由每个节点上运行的 kube-proxy 进程处理。开始的时候, kube-proxy 确实是一个 proxy,等待连接,对每个进来的连接,连接到一个 pod。这称为 userspace(用户空间)代理模式。 后来,性能更好的 iptables 代理模式取代了它。
Service 的 IP 地址是虚拟的, 没有被分配给任何网络接口,当数据包离开节点时也不会列为数据包的源或目的 IP 地址。Service 的一个关键细节是,它们包含一个 IP、端口对,所以服务IP本身并不代表任何东西。这就是为什么你不能够 ping 它们。
service 本身就是一套 iptables 规则,不存在实体,所以也不能 ping 通。
最近在做开源之夏的时候也遇到了这种情况,我还傻傻的在 ping 它。
kube-proxy 如何使用 iptables
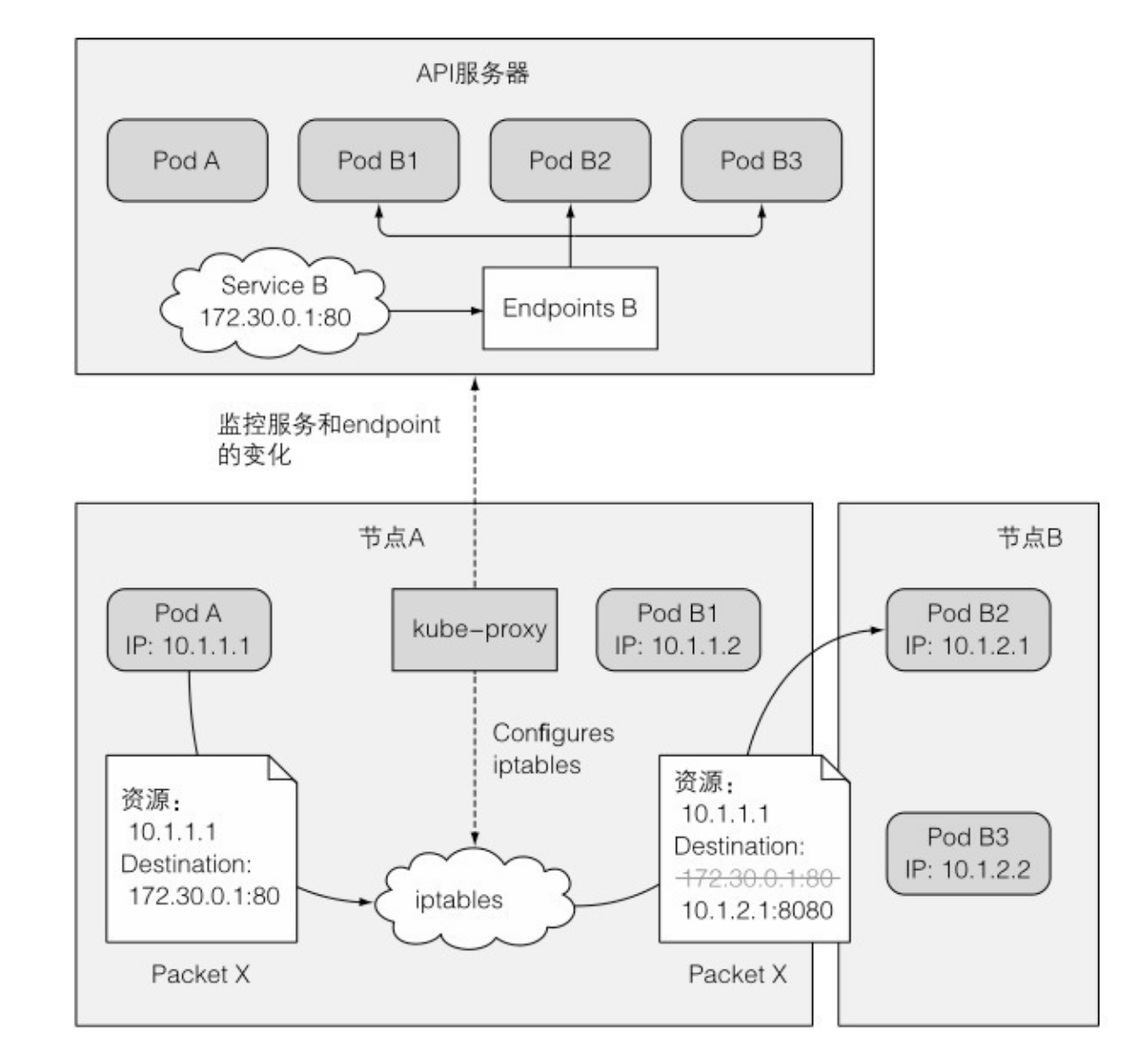
当在 API 服务器中创建一个 service 时,虚拟 IP 地址立刻就会分配给它。之后很短时间内, API服务器会通知所有运行在工作节点上的 kube-proxy 客户端有一个新 service 已经被创建了。然后,每个 kube-proxy 都会让该服务在自己的运行节点上可寻址。原理是通过建立一些 iptables 规则,确保每个目的地为服务的 IP/端口对的数据包被解析,目的地址被修改,这样数据包就会被重定向到支持服务的一个 pod。
除了监控 API 对 Service 的更改, kube-proxy 也监控对 Endpoint 对象的更改。Endpoint 对象保存所有支持服务的 pod 的IP/端口对。这就是为什么 kube-proxy 必须监听所有 Endpoint 对象。毕竟 Endpoint 对象在每次新创建或删除支持 pod 时都会发生变更,当 pod 的就绪状态发生变化或者 pod 的标签发生变化,就会落入或超出服务的范畴(采用就绪探针和存活探针)。
发送数据包给 service 会发生什么?
包目的地初始设置为服务的 IP 和端口(在本例中, Service是在 172.30.0.1:80)。发送到网络之前,节点 A 的内核会根据配置在该节点上的 iptables 规则处理数据包。
内核会检查数据包是否匹配任何这些 iptables 规则。其中有个规则规定如果有任何数据包的目的地 IP等于 172.30.0.1 、目的地端口等于 80,那么数据包的目的地 IP 和端口应该被替换为随机选中的 pod 的 IP 和端口。
4、Apiserver认证机制
ServiceAccount
ServiceAccount是一种运行在 pod中的应用程序和 API服务器身份认证的一种方式。应用程序通过在请求中传递 ServiceAccount token来实现这一点。
ServiceAccount就像 Pod、Secret、ConfigMap等一样都是资源,它们作用在单独的命名空间,为每个命名空间自动创建一个默认的 ServiceAccount(你的pod会一直使用)。 可以像其他资源那样查看ServiceAccount列表:
kubeclt get sa每个 pod 都与一个 ServiceAccount 相关联,但是多个pod可以使用同一个ServiceAccount。pod只能使用同一个命名空间中的ServiceAccount。
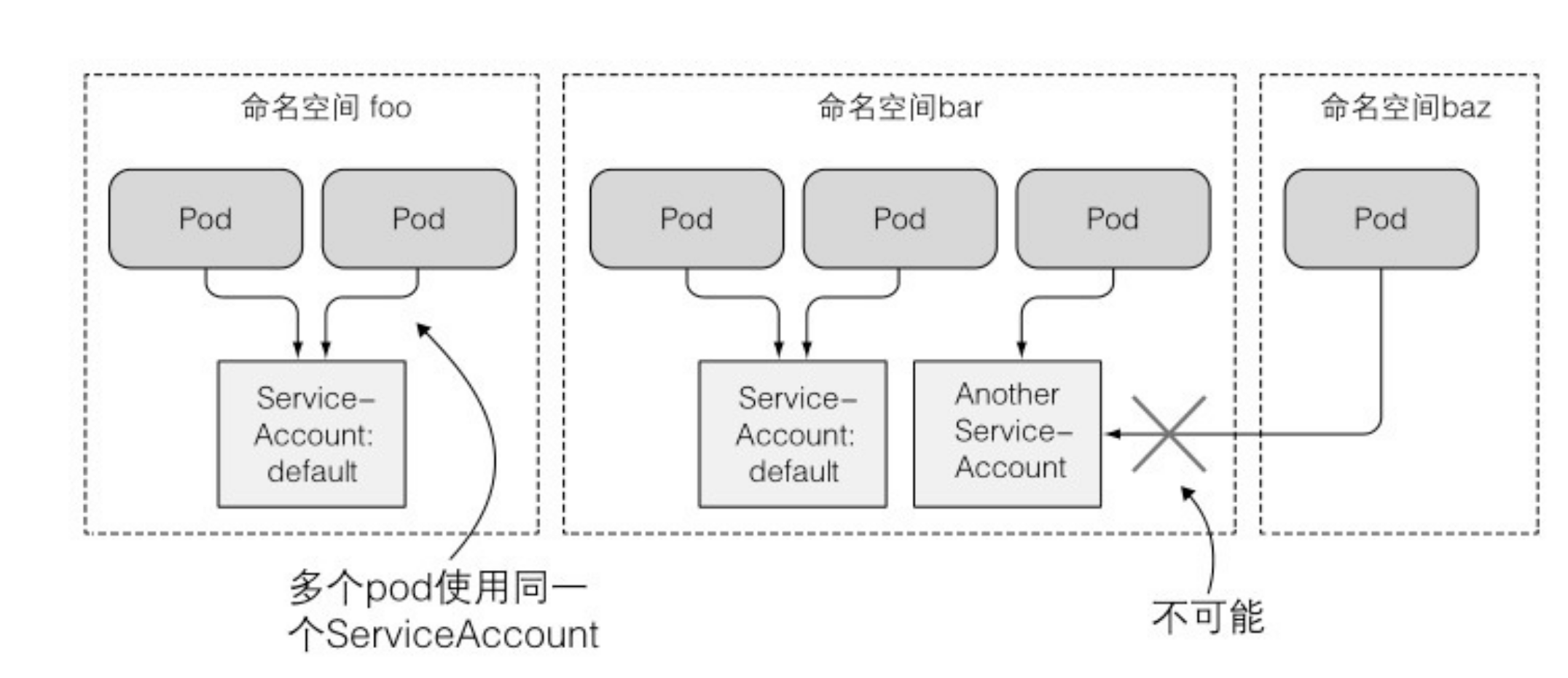
在 pod 的 manifest 文件中,可以用指定账户名称的方式将一个 ServiceAccount 赋值给一个 pod。如果不显式地指定 ServiceAccount的账户名称,pod 会使用在这个命名空间中的默认 ServiceAccount。
当API服务器接收到一个带有认证 token 的请求时,服务器会用这个 token 来验证发送请求的客户端所关联的 ServiceAccount 是否允许执行请求的操作。API服务器通过管理员配置好的系统级别认证插件来获取这些信息。其中一个现成的授权插件是基于角色控制的插件 (RBAC)。
创建ServiceAccount
每个命名空间都拥有一个默认的 ServiceAccount,也可以在需要时创建额外的 ServiceAccount。但是为什么应该费力去创建新的ServiceAccount 而不是对所有的 pod 都使用默认的 ServiceAccount? 显而易见的原因是集群安全性。不需要读取任何集群元数据的 pod 应该运行在一个受限制的账户下,这个账户不允许它们检索或修改部署在集群中的任何资源。需要检索资源元数据的 pod 应该运行在只允许读取这些对象元数据的 ServiceAccount 下。反之,需要修改这些对象的 pod 应该在它们自己的 ServiceAccount 下运行,这些 ServiceAccount 允许修改 API 对象。
kubectl create serviceaccount foo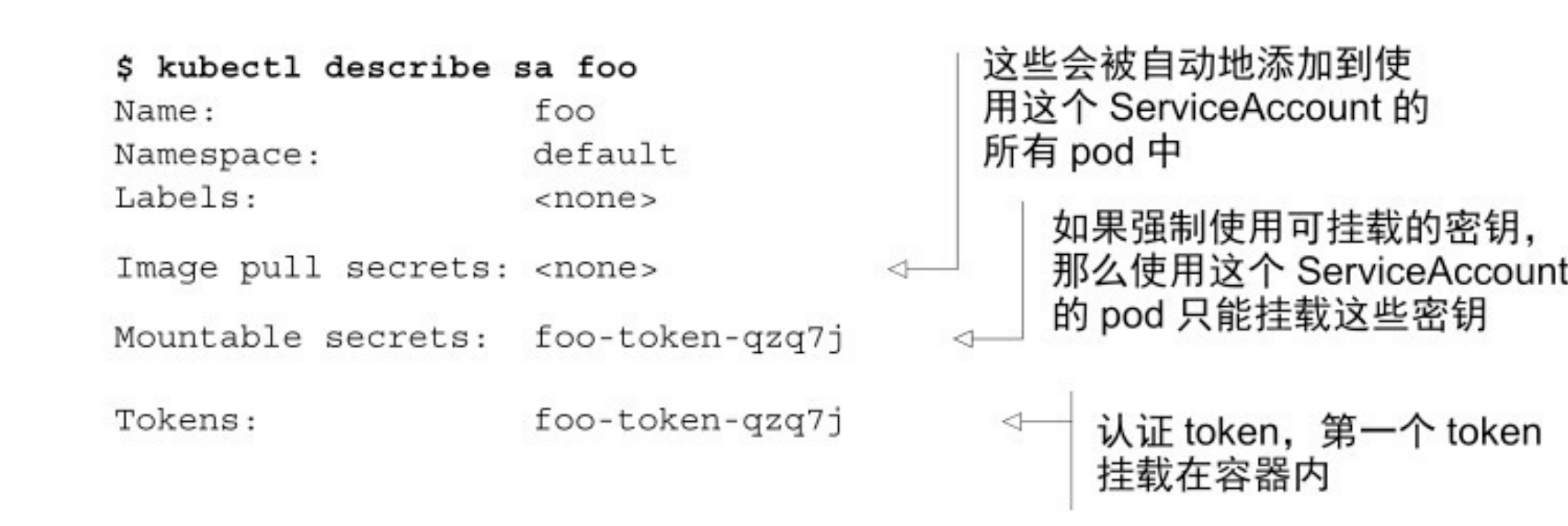
这里 SA 的 token 就和 secret 关联了,可以用kubectl describe secret foo-token-qzq7j查看密钥里面的数据。
将ServiceAccount分配给pod
在创建另外的 ServiceAccount之后,需要将它们赋值给 pod。通过在 pod 定义文件中的 spec.serviceAccountName 字段上设置 ServiceAccount的名称来进行分配。
注意 pod 的ServiceAccount 必须在 pod 创建时进行设置,后续不能被修改。

自定义的 ServiceAccount 可以允许列出pod。这可能是因为集群没有使用 RBAC授权插件,给了所有的 ServiceAccount 全部的权限。 如果集群没有使用合适的授权,创建和使用额外的 ServiceAccount 并没有多大意义,因为即使默认的 ServiceAccount 也允许执行任何操作。
RBAC:基于角色的权限控制 Role-Based Access Control
Kubernetes API服务器可以配置使用一个授权插件来检查是否允许用户请求的动作执行。因为 API服务器对外暴露了 REST 接口,用户可以通过向服务器发送 HTTP请求来执行动作,通过在请求中包含认证凭证来进行认证(认证token、用户名和密码或者客户端证书)。
但是有什么动作?REST客户端发送 GET、POST、 PUT、DELETE 和其他类型的 HTTP 请求到特定的 URL 路径上,这些路径表示特定的 REST 资源。在 Kubernetes 中,这些资源是 Pod、Service、 Secret 等等。
RBAC授权插件将用户角色作为决定用户能否执行操作的关键因素。主体(可以是一个人、一个 ServiceAccount,或者一组用户或ServiceAccount)和一个或多个角色相关联,每个角色被允许在特定的资源上执行特定的动词。
如果一个用户有多个角色,他们可以做任何他们的角色允许他们做的事情。如果用户的角色都没有包含对应的权限,例如,更新密 钥,API服务器会阻止用户3个“他的”对密钥执行PUT或PATCH请求。
通过 RBAC 插件管理授权是简单的,这一切都是通过创建四种 RBAC 特定的 Kubernetes 资源来完成的。
RBAC授权规则是通过四种资源来进行配置的,它们可以分为两个组:
Role(角色)和ClusterRole(集群角色),它们指定了在资源上可以执行哪些动词。
RoleBinding (角色绑定)和 ClusterRoleBinding (集群角色绑定),它们将上述角色绑定到特定的用户、组或ServiceAccounts上。
角色定义了可以做什么操作,而绑定定义了谁可以做这些操作
角色和角色绑定是命名空间的资源,而集群角色和集群角色绑定是集群级别的资源(不是命名空间的)
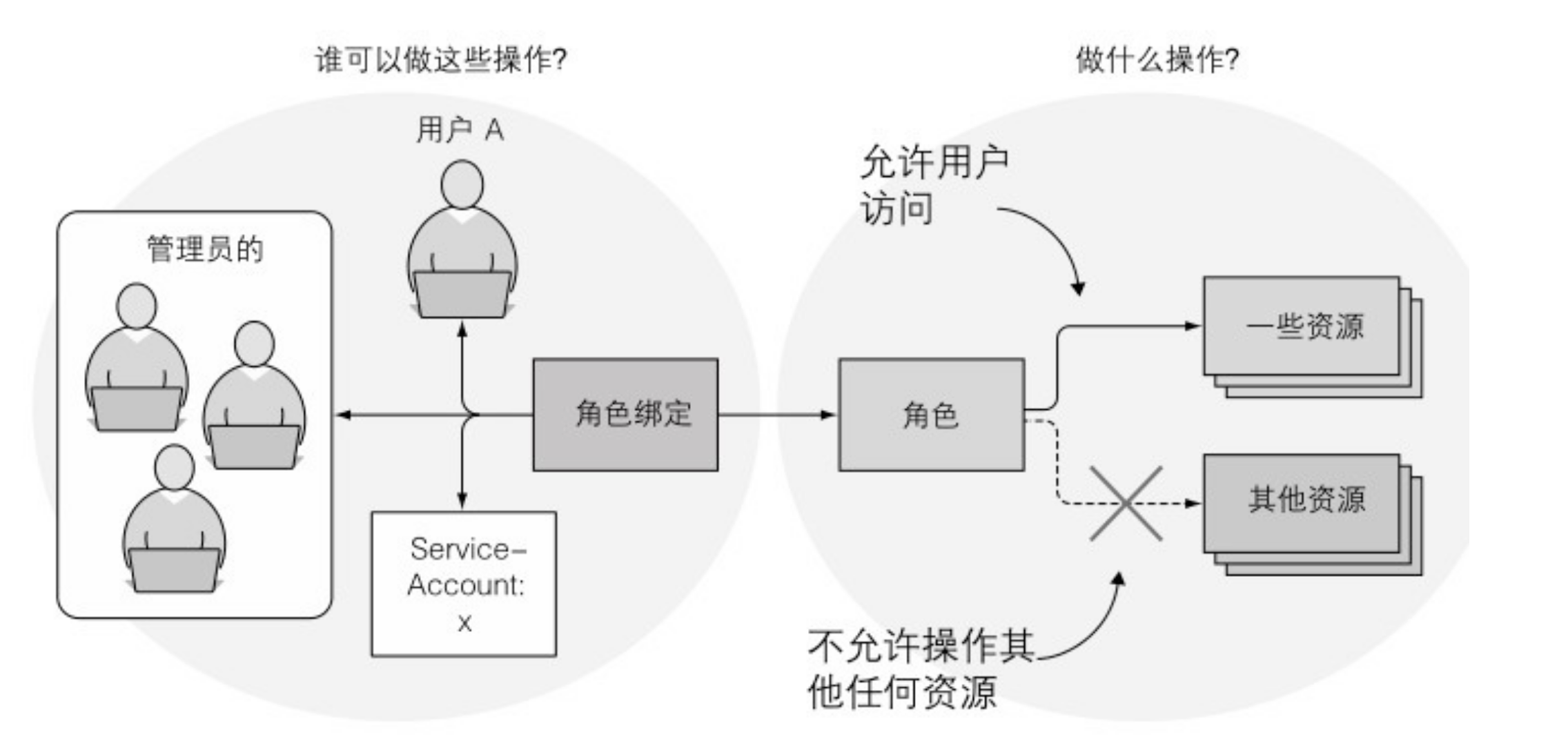
Pod -> ServiceAccount -> RoleBinding -> Role
1、创建一个 Role 或 ClusterRole,定义所需的权限。
2、创建一个 RoleBinding 或 ClusterRoleBinding,将 Role 或 ClusterRole 绑定到一个或多个主体(如 ServiceAccount)。
3、当一个 Pod 使用某个 ServiceAccount 运行时,该 Pod 继承了该 ServiceAccount 所关联的角色的权限。
因此,RBAC 的权限是通过 ServiceAccount 绑定到 Pod 的,而不是直接绑定到 Pod 本身。这样可以集中管理权限,并使权限与具体的工作负载解耦。

5、静态Pod
静态 Pod 直接由特定节点上的kubelet进程来管理,不通过 master 节点上的apiserver。无法与我们常用的控制器Deployment或者DaemonSet进行关联,它由kubelet进程自己来监控,当pod崩溃时重启该pod,kubelet也无法对他们进行健康检查。静态 pod 始终绑定在某一个kubelet,并且始终运行在同一个节点上(Pod 的节点不是由 k8s 调度器选取,而是直接选定 kubelet 所在的节点)。 kubelet会自动为每一个静态 pod 在 Kubernetes 的 apiserver 上创建一个镜像 Pod(Mirror Pod),因此可以在 apiserver 中查询到该 pod,但是不能通过 apiserver 进行控制(例如不能删除)。
创建静态 Pod 有两种方式:配置文件和 HTTP 两种方式。
配置文件就是放在特定目录下的标准的 JSON 或 YAML 格式的 pod 定义文件。用kubelet --pod-manifest-path=<the directory>来启动kubelet进程,kubelet 定期的去扫描这个目录,根据这个目录下出现或消失的 YAML/JSON 文件来创建或删除静态 pod。
例如:kubelet --pod-manifest-path=/etc/kubernetes/manifests
[root@ node01 ~] $ cat <<EOF >/etc/kubernetes/manifests/static-web.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
app: static
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
EOF在这个文件创建后,kubelet会自动根据这个文件创建 Pod。
运行中的kubelet周期扫描配置的目录(我们这个例子中就是/etc/kubernetes/manifests)下文件的变化,当这个目录中有文件出现或消失时创建或删除 pod。
用 kubeadm 安装的集群,master 节点上面的几个重要组件都是用静态 Pod 的方式运行的,我们登录到 master 节点上查看/etc/kubernetes/manifests目录:

6、Controller Manager
根据官方文档的说法:kube-controller-manager 运行控制器,它们是处理集群中常规任务的后台线程。
说白了,Controller Manager 就是集群内部的管理控制中心,由负责不同资源的多个 Controller 构成,共同负责集群内的 Node、Pod 等所有资源的管理,比如当通过 Deployment 创建的某个 Pod 发生异常退出时,RS Controller 便会接受并处理该退出事件,并创建新的 Pod 来维持预期副本数。
几乎每种特定资源都有特定的 Controller 维护管理以保持预期状态,而 Controller Manager 的职责便是把所有的 Controller 聚合起来:
提供基础设施降低 Controller 的实现复杂度
启动和维持 Controller 的正常运行
可以这么说,Controller 保证集群内的资源保持预期状态,而 Controller Manager 保证了 Controller 保持在预期状态。
kube-controller-manager 是 Kubernetes 控制面里的一个二进制,它里面打包了很多官方内置的 controller,比如:
NodeController
ReplicationController
Deployment/ReplicaSet 相关的(现在实现上更细一点)
ServiceAccountController
NamespaceController
EndpointSliceController
Job/CronJobController
PV/PVC 绑定、垃圾回收相关的控制器
……
这些都是 Kubernetes 项目自身维护、编译进 kube-controller-manager 二进制里的。

