

NUMA
参考:https://developer.aliyun.com/article/1282880、https://support.huaweicloud.com/intl/zh-cn/usermanual-cce/cce_10_0425.html
1、NUMA的由来
NUMA(Non-Uniform Memory Access),即非一致性内存访问,是一种关于多个CPU如何访问内存的架构模型,早期,在计算机系统中,CPU是这样访问内存的:
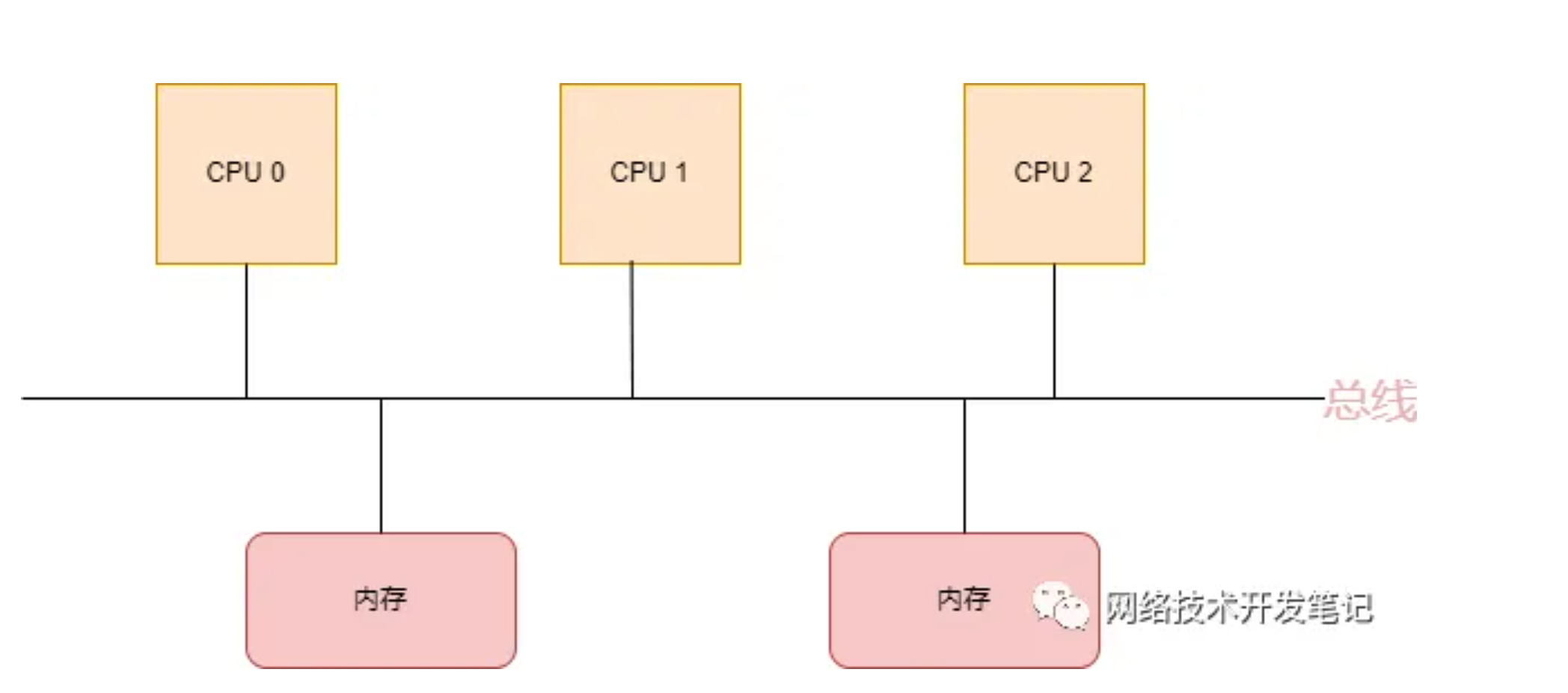
在这种架构中,所有的CPU都是通过一条总线来访问内存,我们把这种架构叫做SMP架构(Symmetric Multi-Processor),也就是对称多处理器结构。可以看出来,SMP架构有下面4个特点:
CPU和CPU以及CPU和内存都是通过一条总线连接起来
CPU都是平等的,没有主从关系
所有的硬件资源都是共享的,即每个CPU都能访问到任何内存、外设等
内存是统一结构和统一寻址的(UMA, Uniform Memory Architecture)
SMP架构在CPU核不多的情况下,问题不明显,有实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU:
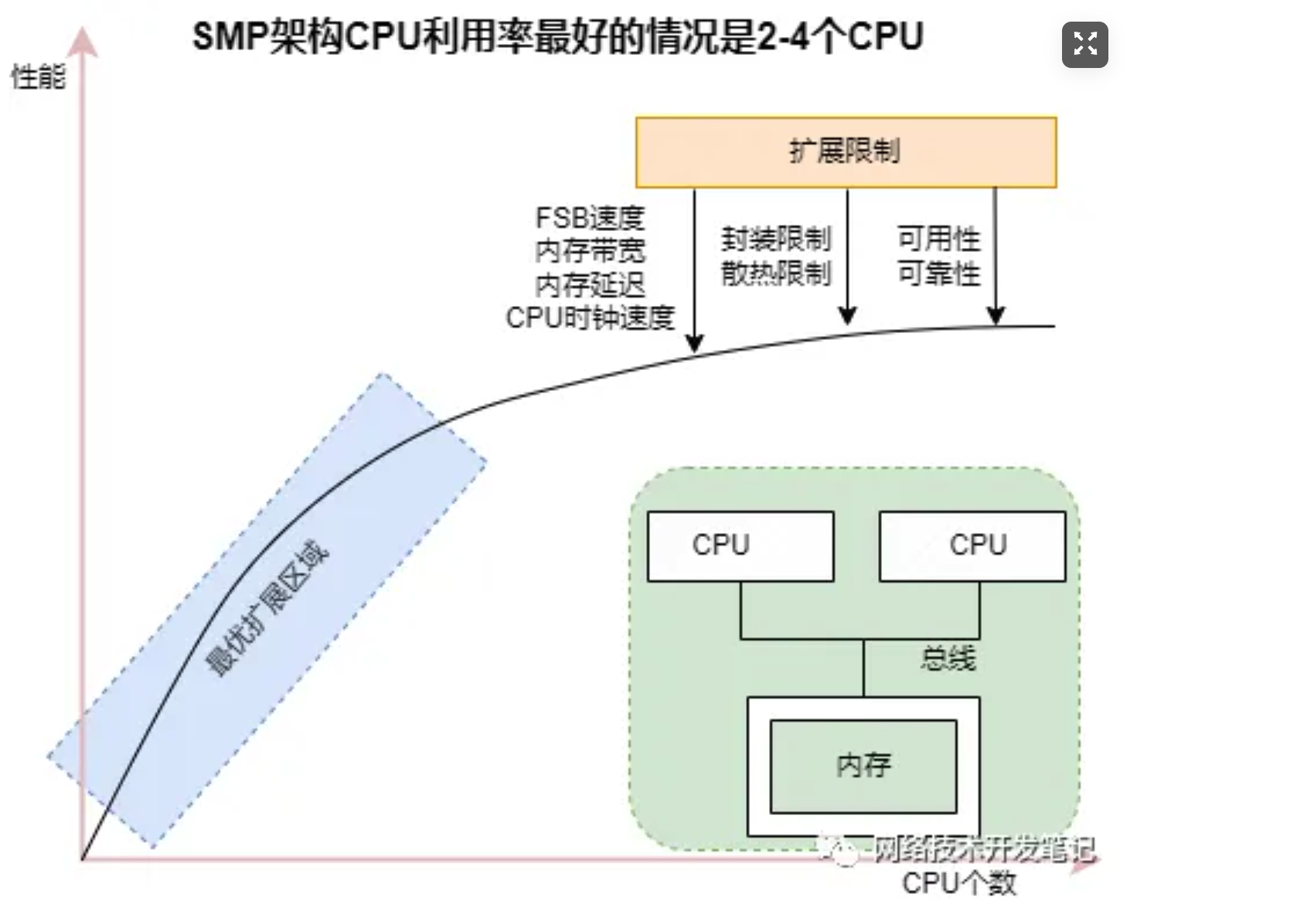
但是随着CPU多核技术的发展,一颗物理CPU中集成了越来越多的core,导致SMP架构的性能瓶颈越来越明显,因为所有的处理器都通过一条总线连接起来,因此随着处理器的增加,系统总线成为了系统瓶颈,另外,处理器和内存之间的通信延迟也较大。
为了解决SMP架构下不断增多的CPU Core导致的性能问题,NUMA架构应运而生,NUMA调整了CPU和内存的布局和访问关系,具体示意如下图:
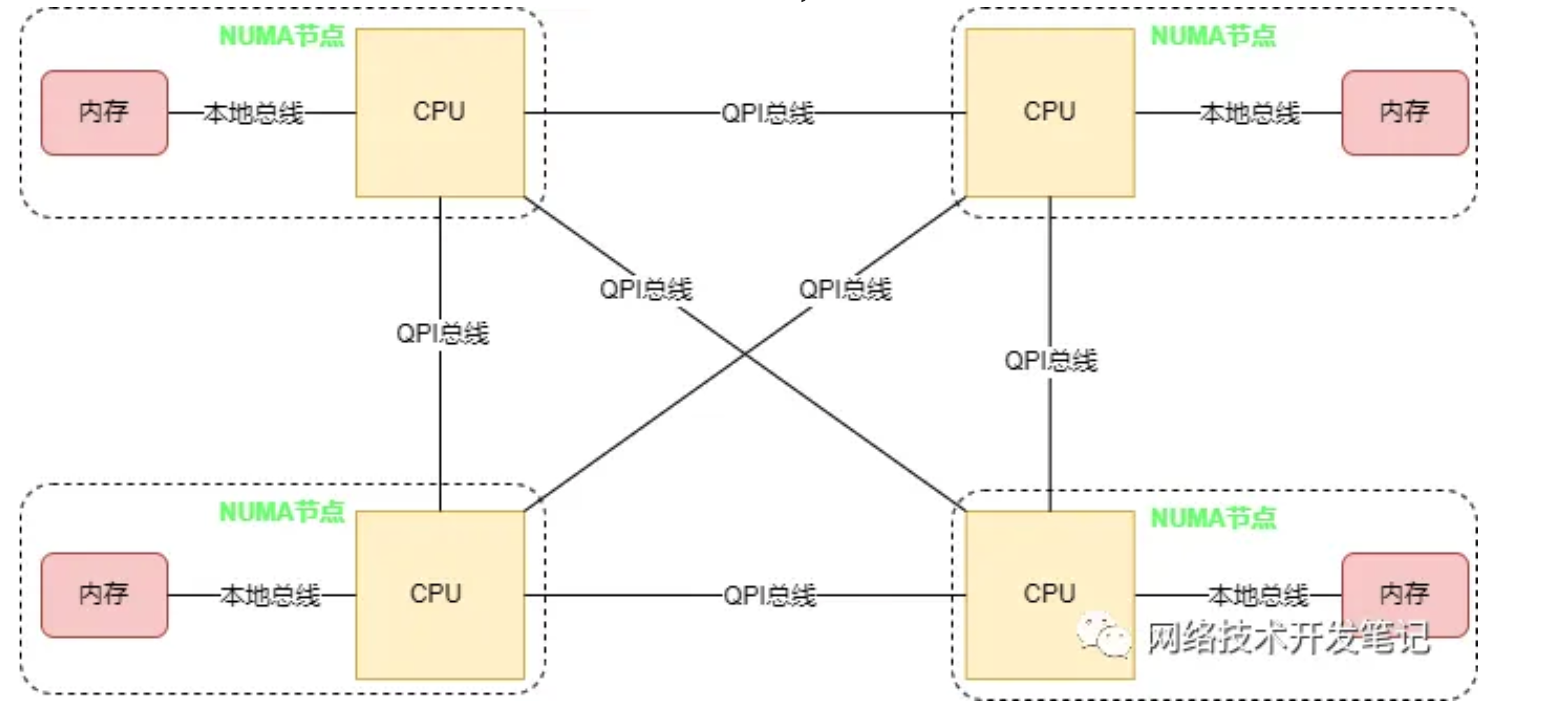
在NUMA架构中,将CPU划分到多个NUMA Node中,每个Node有自己独立的内存空间和PCIE总线系统。各个CPU间通过QPI总线进行互通。
CPU访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访,问速度越慢,所以叫做非一致性内存访问,这个访问内存的距离我们称作Node Distance。
虽然NUMA很好的解决了SMP架构下CPU大量扩展带来的性能问题,但是其自身也存在着不足,当Node节点本地内存不足时,需要跨节点访问内存,节点间的访问速度慢,从而也会带来性能的下降。所以我们在编写应用程序时,要充分利用NUMA系统的这个特点,尽量的减少不同CPU模块之间的交互,避免远程访问资源,如果应用程序能有方法固定在一个CPU模块里,那么应用的性能将会有很大的提升。
2、NUMA架构下的CPU和内存分布
在Linux系统上,可以查看到NUMA架构下CPU和内存的分布情况,不过在这之前,我们先得理清几个概念:
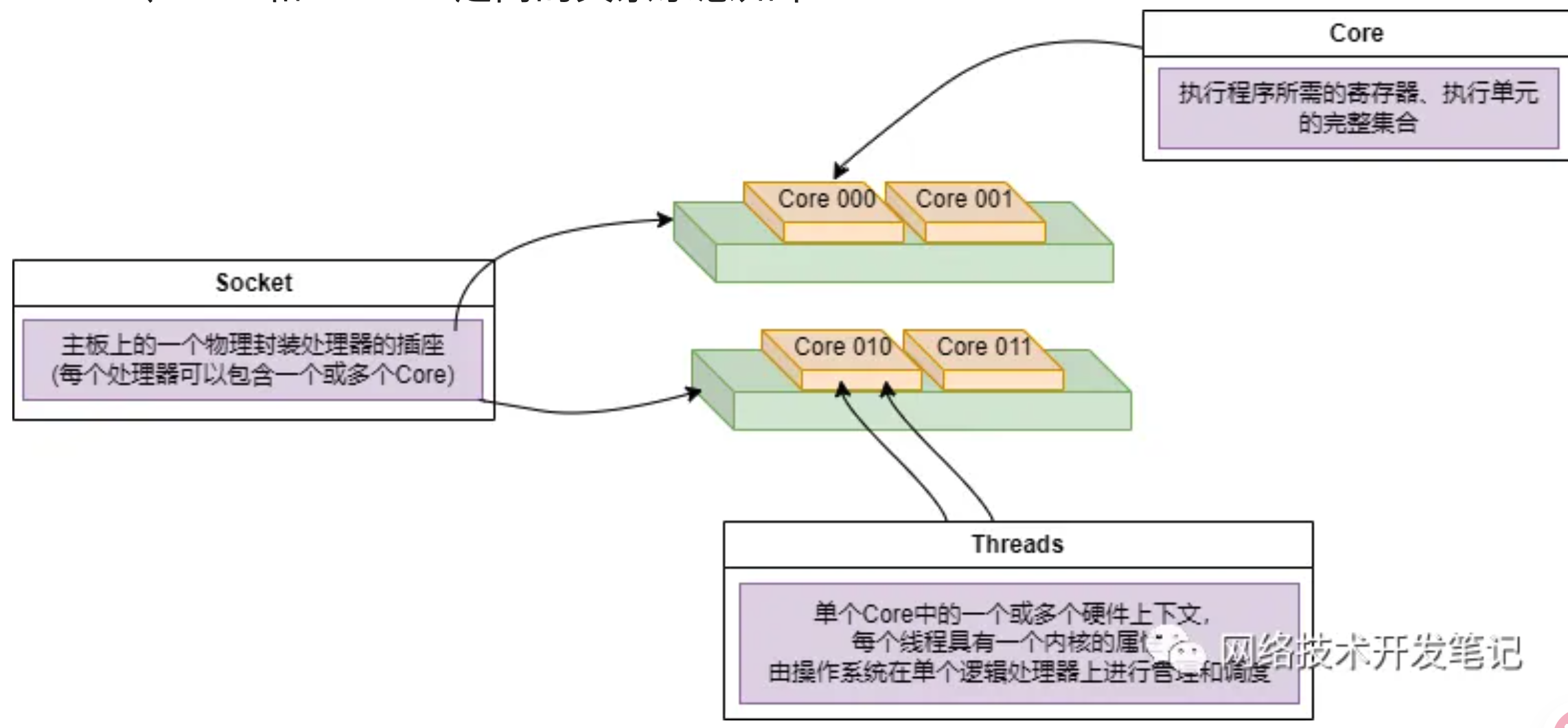
Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽,Socket表示可以看得到的真实的CPU核 。
Core:物理 CPU 封装内的独立的一组程序执行的硬件单元,比如寄存器,计算单元等,Core表示的是在同一个物理核内逻辑层面的核。同一个物理CPU的多个Core,有自己独立的L1和L2 Cache,共享L3 Cache。
Thread:使用超线程技术虚拟出来的逻辑 Core,需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread 。超线程可以在一个逻辑核等待指令执行的间隔(等待从cache或内存中获取下一条指令),把时间片分配到另一个逻辑核。高速在这两个逻辑核之间切换,让应用程序感知不到这个间隔,误认为自己是独占了一个核。对于每个逻辑线程,拥有完整独立的寄存器集合和本地中断逻辑,共享执行单元和一二三级Cache,超线程技术可以带来20%~30%的性能提升。
Node:即NUMA Node,包含有若干个 CPU Core 的组。
Socket、Core和Threads之间的关系示意如下:
在Linux系统中,可以用lscpu查看NUMA和CPU的对应关系:
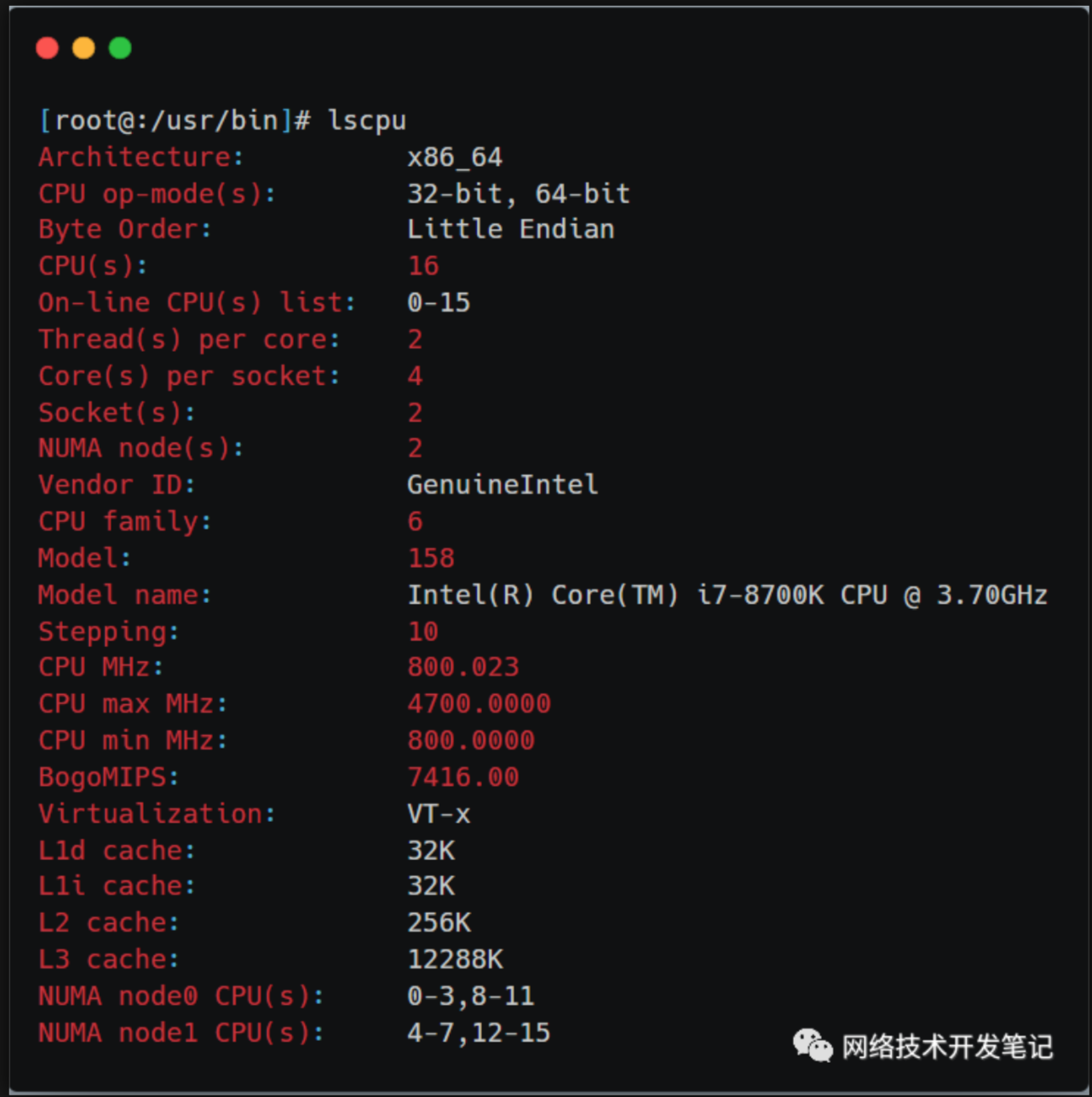
从上图可以看到,这台服务器有两个NUMA node,有两个Socket,每个Socket也就是一个物理CPU,有4个逻辑Core,每个逻辑Core有两个线程(服务器开启了超线程),所以总共的CPU个数(以超线程计数)为:2*4*2 = 16个。
使用numactl -H命令可以看到NUMA下的内存分布:
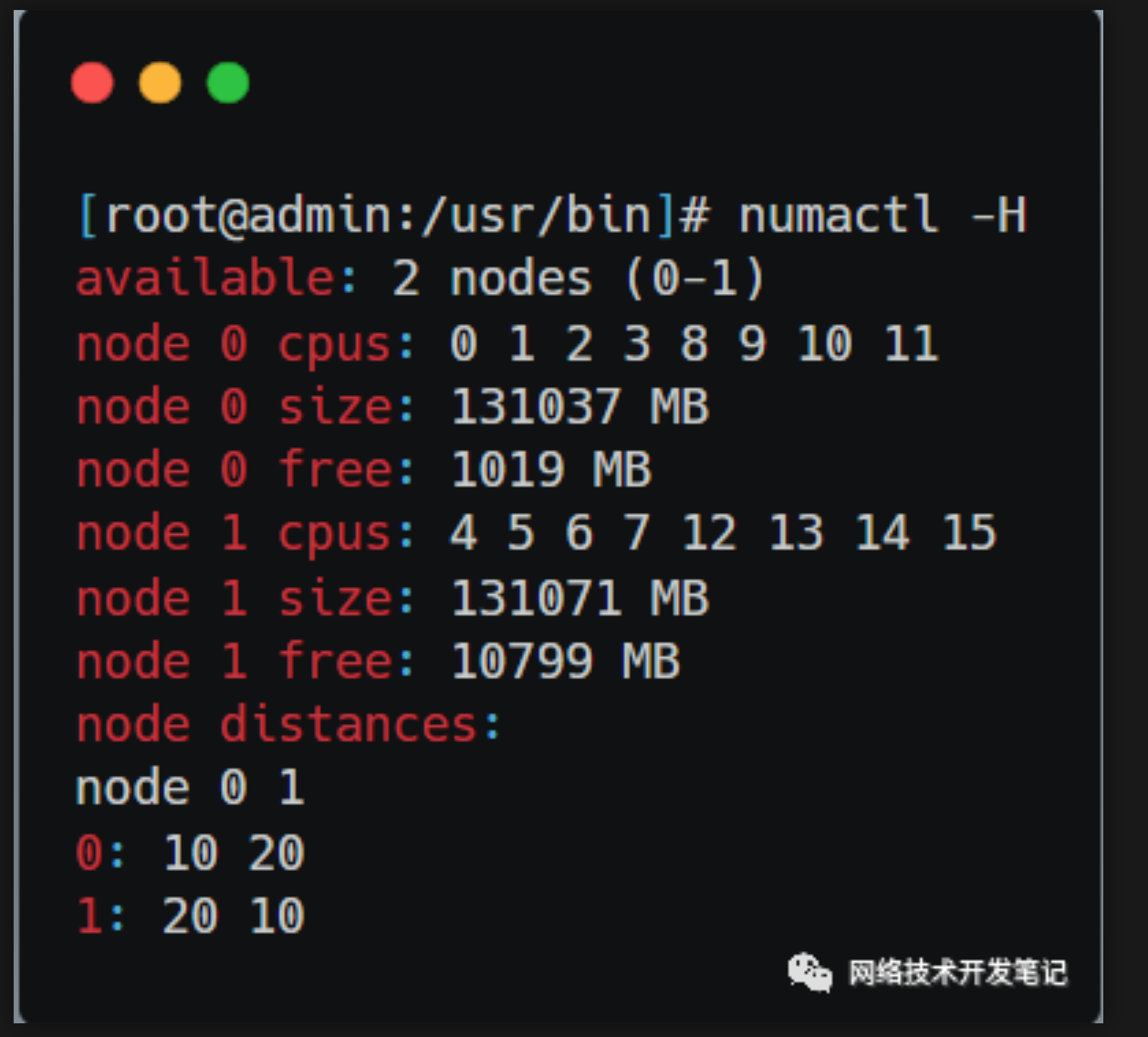
所以这台服务器上CPU和内存在NUMA下的分布如下:
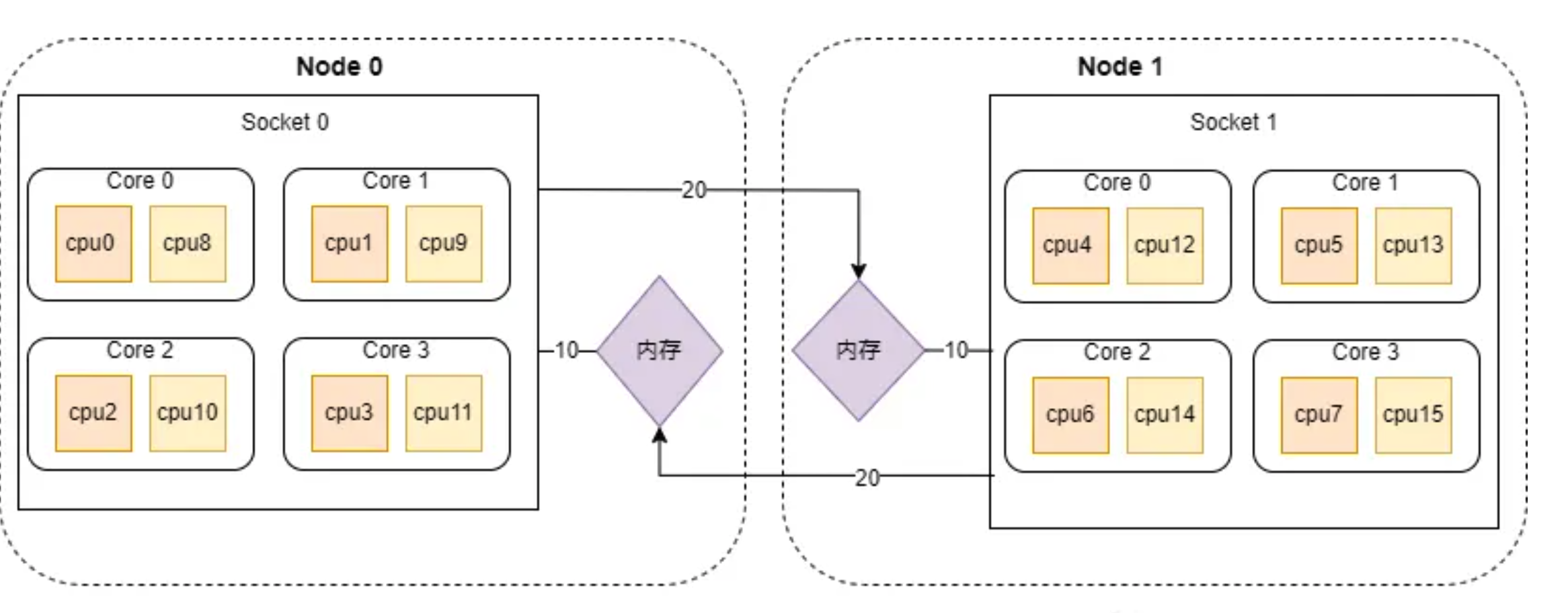
NUMA架构下的CPU,先从逻辑Core开始编号,如果开启了超线程,就从Core总数的后面继续编号,例如上图中从cpu8开始之后的都是开启超线程之后的CPU线程。
3、NUMA架构下的编程
NUMA架构显著的特点就是CPU访问本地内存快,访问远程内存慢。所以我们在NUMA架构下编写程序,要扬长避短,多核多线程编程中,我们要尽可能的利用CPU Core的亲和性,将线程绑定到对应的CPU上,并且该线程从该CPU对应的本地内存上去申请内存,这样才能最大限度发挥NUMA架构的优势,达到比较好的处理性能。
简单来说,就是本地的处理器、本地的内存来处理本地的设备上产生的数据。如果有一个PCI设备(比如网卡)在Node0上,就用Node0上的核来处理该设备,处理该设备用到的数据结构和数据缓冲区都从Node0上分配。在DPDK中,有一个rte_socket_id()函数,可以获取当前线程所在的NUMA Node,在使用DPDK提供申请内存的接口中,一般都需要传入参数NUMA id,也是基于提高NUMA架构下的报文转发性能考虑。
4、Volcano的NUMA亲和性调度
在云原生环境中,对于高性能计算(HPC)、实时应用和内存密集型工作负载等需要CPU间通信频繁的场景下,跨NUMA节点访问会导致增加延迟和开销,从而降低系统性能。为此,volcano提供了NUMA亲和性调度能力,尽可能把Pod调度到需要跨NUMA节点最少的工作节点上,这种调度策略能够降低数据传输开销,优化资源利用率,从而增强系统的整体性能。
假设单个节点CPU总量为32U,由2个NUMA节点提供资源,分配如下:
Pod设置拓扑策略后,调度情况如图1所示。
当Pod的CPU申请值为9U时,设置拓扑策略为“best-effort”,Volcano会匹配拓扑策略同样为“best-effort”的节点-1,且该策略允许调度至多个NUMA节点,因此9U的申请值会被分配到2个NUMA节点,该Pod可成功调度至节点-1。
当Pod的CPU申请值为11U时,设置拓扑策略为“restricted”,Volcano会匹配拓扑策略同样为“restricted”的节点-2/节点-3,且单NUMA节点CPU总量满足11U的申请值,但单NUMA节点剩余可用的CPU量无法满足,因此该Pod无法调度。
当Pod的CPU申请值为17U时,设置拓扑策略为“restricted”,Volcano会匹配拓扑策略同样为“restricted”的节点-2/节点-3,且单NUMA节点CPU总量无法满足17U的申请值,可允许分配到2个NUMA节点,该Pod可成功调度至节点-3。
当Pod的CPU申请值为17U时,设置拓扑策略为“single-numa-node”,Volcano会匹配拓扑策略同样为“single-numa-node”的节点,但由于单NUMA节点CPU总量均无法满足17U的申请值,因此该Pod无法调度。


